
Usage notes
-
Calculate Density requires an input DataFrame containing point geometries.
-
Density can optionally be calculated using one or more count fields specified using
set. A count field is a numerical field that specifies the number of incidents at each location. For example, records representing objects such as cities can use a count field when calculating the density of population. If you specify a count field, the density will be calculated for the count field in addition to the density of points.Fields() -
Input points are aggregated into bins for analysis. You must specify the bin size to aggregate data into using
set. By default, output results will be in square kilometers.Bins() -
Input points are aggregated into bins of a specified size and shape (hexagon or square). Specify the bin shape using the
binparameter in the_type setsetter. If you are aggregating into hexagons, the bin size is the height of each hexagon, and the radius of the resulting hexagon will be the height divided by the square root of three. If you are aggregating into squares, the bin size is the height of the square, which is equal to the width.Bins

-
You must specify a neighborhood size that is greater than the bin size. The neighborhood size (set by
set) is used to find input records within the same neighborhood as the row (bin) of interest.Neighborhood() -
Larger values of the neighborhood size produce a more generalized density output. Smaller values produce an output that shows more detail.
-
Only points that fall within a neighborhood are considered when calculating the density. If no points fall within the neighborhood of a particular bin, that bin is not assigned a value.
-
There are two weighting options to calculate density: The
Uniformoption sums all the values within the neighborhood and divides them by the area. TheKerneloption weights values in the neighborhood by distance from the record of interest and applies a kernel function to fit a smooth tapered surface to each point. Usesetto specify the weighting option.Weight Type() -
Only areas within the neighborhood of a bin containing points will be returned.
-
If the area unit scale factor is small relative to the distance between the points, the output values may also be very small. To obtain larger values, use the area unit scale factor for larger units (for example, use
Squarerather thanKilometers Square).Meters -
Analysis with binning requires that your input DataFrame's geometry has a projected coordinate system. If your data is not in a projected coordinate system, the tool will transform your input to a World Cylindrical Equal Area (SRID: 54034) projection. You can transform your data to a projected coordinate system by using ST_Transform.
-
The density values will always be floating point.
-
Optionally, you can calculate density using time stepping. Each time step is analyzed independent of input rows with time values outside the time step. To use time stepping, your input data must be time enabled and represent an instant in time. When time stepping is applied, output rows will be time intervals represented by start and end time fields.
-
When input records are analyzed using time steps, each time step is analyzed independent of records outside of the time step.
Limitations
Density can be calculated for point geometries only.
Results
| Field | Description |
|---|---|
density | The density of the given polygon. This is returned in the specified unit scale factor. |
density | The density weighted by the given field. This is only returned when one or more fields are specified. |
step | When time stepping is specified, output polygons will have a time interval. This field represents the start time. |
step | When time stepping is specified, output polygons will have a time interval. This field represents the end time. |
bin | The geometry of the result bins. |
To plot the results of Calculate Density analysis, consider using the following plotting variables:
- Column values:
density - Symbology type: natural breaks (Jenks)
- Color type: continuous colors
Performance notes
Improve the performance of Calculate Density by doing one or more of the following:
-
Only analyze the records in your area of interest. You can pick the records of interest by using one of the following SQL functions:
- ST_Intersection—Clip to an area of interest represented by a polygon. This will modify your input records.
- ST_BboxIntersects—Select records that intersect an envelope.
- ST_EnvIntersects—Select records having an evelope that intersects the envelope of another geometry.
- ST_Intersects—Select records that intersect another dataset or area of intersect represented by a polygon.
- Larger bins will perform better than smaller bins. If you are unsure about which size to use, start with a larger bin to prototype.
- Similar to bins, larger time steps will perform better than smaller time steps.
- Decrease the ratio of the neighborhood size to the bin size. A neighborhood size that is three times the size of the bin will perform better than one that is 10 times the bin size.
Similar capabilities
Syntax
For more details, go to the GeoAnalytics Engine API reference for calculate density.
| Setter | Description | Required |
|---|---|---|
run(dataframe) | Runs the Calculate Density tool using the provided DataFrame. | Yes |
set | Sets the desired output units of the density values. The default is '. | No |
set | Sets the size and shape of bins used to calculate density. | Yes |
set | Sets one or more fields specifying the number of incidents at each location. You can calculate the density on multiple fields. The density of the count of points will always be calculated. | No |
set | Sets the size of the neighborhood within which to calculate density. The distance must be larger than the bin size. | Yes |
set | Sets the time step interval, time step repeat, and reference time. If set, density will be calculated for each time step at each bin location. The input DataFrame must have a datetime column to use this feature. | No |
set | Sets the type of weighting applied to density calculations. This parameter supports two options: ' (default) and '. | No |
Examples
Run Calculate Density
# Log in
import geoanalytics
geoanalytics.auth(username="myusername", password="mypassword")
# Imports
from geoanalytics.tools import CalculateDensity
from geoanalytics.sql import functions as ST
from pyspark.sql import functions as F
# Path to the earthquakes data
data_path = r"https://sampleserver6.arcgisonline.com/arcgis/rest/services/" \
"Earthquakes_Since1970/FeatureServer/0"
# Create an earthquakes DataFrame transform geometry to Greek Grid (2100)
earthquakes_df = spark.read.format("feature-service").load(data_path) \
.withColumn("shape", ST.transform("shape", 2100))
# Create a DataFrame for earthquakes near Greece using ST_EnvIntersects
greece_earthquakes_df = earthquakes_df.withColumn("near_greece",
ST.bbox_intersects("shape",
xmin=100000,
xmax=1100000,
ymin=3500000,
ymax=4800000)) \
.where("near_greece = true")
# Use Calculate Density to find areas with a high density of earthquake occurrences
result = CalculateDensity() \
.setWeightType(weight_type="Uniform") \
.setBins(bin_size=10, bin_size_unit="Miles", bin_type="Square") \
.setNeighborhood(distance=50, distance_unit="Miles") \
.setAreaUnit(area_unit="SquareMiles") \
.run(dataframe=greece_earthquakes_df)
# Show the first 5 rows of the result DataFrame
result.select("bin_geometry", F.round("density",9).alias("density")).sort("density", ascending=False).show(5)+--------------------+-----------+
| bin_geometry| density|
+--------------------+-----------+
|{"rings":[[[28968...|0.001234568|
|{"rings":[[[22530...|0.001234568|
|{"rings":[[[22530...|0.001234568|
|{"rings":[[[22530...|0.001234568|
|{"rings":[[[22530...|0.001234568|
+--------------------+-----------+
only showing top 5 rowsPlot results
# Create a continents DataFrame and transform geometry to Greek Grid (2100)
continents_path = "https://services.arcgis.com/P3ePLMYs2RVChkJx/ArcGIS/rest" \
"/services/World_Continents/FeatureServer/0"
continents_subset_df = spark.read.format("feature-service").load(continents_path) \
.where("CONTINENT = 'Europe' or CONTINENT = 'Asia'") \
.withColumn("shape", ST.transform("shape", 2100))
# Plot the Calculate Density result with the continents data
result_plot = result.st.plot(cmap_values="density",
cmap="YlOrRd",
legend=True,
figsize=(14,8),
basemap="light")
result_plot = continents_subset_df.st.plot(facecolor="none",
edgecolors="black",
ax=result_plot)
result_plot.set_title("Density of earthquakes near Greece (1970 - 2009)")
result_plot.set_xlabel("X (Meters)")
result_plot.set_xlim(30000, 1140000)
result_plot.set_ylabel("Y (Meters)")
result_plot.set_ylim(3690000, 4950000);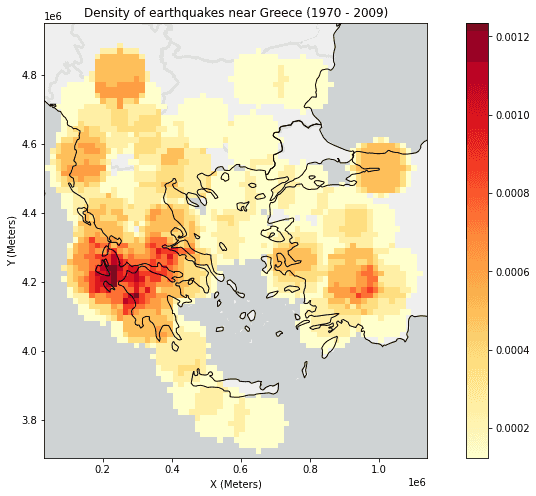
Version table
| Release | Notes |
|---|---|
1.0.0 | Python tool introduced |