Detect Incidents examines time-sequential records using a specified condition. Records that meet the condition are marked as incidents. The result contains the input DataFrame records, with additional fields stating if the record is an incident, the status of the incident, the duration of the incident, and a unique incident identifier.
Usage notes
- The following table outlines terminology for Detect Incidents:
| Term | Description |
|---|---|
| Track | A sequence of records that are time enabled with time type instant. Records are determined to be in the sequence by a track identifier field and are ordered by time. For example, a city could have a fleet of snowplow trucks that record their location every 10 minutes. The vehicle ID could represent the distinct tracks. |
| Incident | Records that meet a condition of interest. |
| Instant | A single moment in time represented by a start time and no end time. Inputs to Detect Incidents must have a time type of instant. Learn how to enable time on a data frame. |
| Interval | A duration of time represented by a start and an end time. |
| Record of interest | Describes the record being analyzed. During analysis, all records are analyzed. |
-
Detect Incidents will create a new output. It will not modify the input DataFrame.
-
Detect Incidents can be completed on DataFrames that are tabular or have a geometry. The input DataFrame must have an instant timestamp.
-
Only input records that have a time value will be used. Any record that does not have a time value will be excluded from analysis.
-
Tracks are represented by the unique combination of one or more track fields. For example, if the
flightandID Destinationfields are used as track identifiers, the recordsI,D007 SoldenandI,D007 Tokyowould be in different tracks since they have different values for theDestinationfield. -
Conditions are created using Arcade expressions. A start condition is required, and an end condition is optional. If you only apply a start condition, the incident starts when the start condition is evaluated as true and ends when the start condition is evaluated as false. For example, if values in a track are
[0, 10, 15, 20, 40, 10, 12, -2, -12 ]and the start condition is$feature['values' ] > 15, the rows that are incidents are those with[and would beTrue] [0, where only values above 15 are incidents. If you apply an end condition of: False, 10 : False, 15 : False, 20 : True, 40 : True, 10 : False, 12 : False, -2 : False, -12 : False ] $feature['values' ] < 0, the results would be[0. In this example, the incident starts when the start condition is met, and each sequential row is an incident until the end condition is true. These examples are outlined in the following table:: False, 10 : False, 15 : False, 20 : True, 40 : True, 10 : True, 12 : True, -2 : False, -12 : False ]
| Position | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Value | 0 | 10 | 15 | 20 | 40 | 10 | 12 | -2 | -12 |
Start: $feature['values' ] > 15 and no End | False | False | False | True | True | False | False | False | False |
Start: $feature['values' ] > 15 and End: $feature ['values' ] < 0 | False | False | False | True | True | True | True | False | False |
-
Applying a time interval segments tracks at a defined interval. For example, if you set a value of 1 day using
set, and a value of 9:00 a.m. on January 1, 1990 using theTime Boundary Split() timeparameter, each track will be truncated at 9:00 a.m. every day. This split accelerates computing time, as it creates smaller tracks for analysis. If splitting by a recurring time interval boundary makes sense for your analysis, it is recommended for big data processing._boundary _reference -
Conditions can be track aware.
-
A track can have multiple incidents.
-
The duration of an incident is calculated in milliseconds as the time of the record of interest minus the start of an incident. The duration is only calculated if the record has a status of
Started,On, orGoing Ended. The duration for a row with the status ofStartedis always 0.
Limitations
The input must be a time-enabled DataFrame of type instant. Any records that do not have time will not be included in the output.
Results
Results will include the fields from the input DataFrame as well as the following additional fields:
| Field | Description | Notes |
|---|---|---|
Incident | A unique ID given to every row that is an incident. | |
Incident | A string field representing the status of an incident. The value will be null if the row is not an incident, Started if the row is the first incident to meet the start condition, On if the row is still an incident, and Ended when a row is no longer an incident. A single track can have multiple segments of incidents. For example, a track with values [0, 10, 15, 20, 40, 10, 12, -2, -12] and a start condition of $feature['values' ] > 15 will result in Incident values of [0. | |
Incident | The length of time, in milliseconds, an incident occurs. This is calculated as the difference between the record of interest and the record that started the incident. |
Performance notes
Improve the performance of Detect Incidents by doing one or more of the following:
-
Only analyze the records in your area of interest. You can pick the records of interest by using one of the following SQL functions:
- ST_Intersection—Clip to an area of interest represented by a polygon. This will modify your input records.
- ST_BboxIntersects—Select records that intersect an envelope.
- ST_EnvIntersects—Select records having an evelope that intersects the envelope of another geometry.
- ST_Intersects—Select records that intersect another dataset or area of intersect represented by a polygon.
- Specify
Incidentsas the value for theoutputparameter in the_type setsetter.Output Mode() - Split your tracks using
set.Time Boundary Split()
Similar capabilities
Syntax
For more details, go to the GeoAnalytics Engine API reference for detect incidents.
| Setter | Description | Required |
|---|---|---|
run(dataframe) | Runs the Detect Incidents tool using the provided DataFrame. | Yes |
set | Sets the condition used to end incidents. If there is an end condition, any record that meets the start condition expression and does not meet the end condition expression is an incident. | No |
set | Sets which observations are returned. Choose from ' (default) or '. | No |
set | Sets the condition used to start incidents. If there is no end condition expression specified, any record that meets this condition is an incident. If there is an end condition, any record that meets the start condition expression and does not meet the end condition expression is an incident. | Yes |
set | Sets boundaries to limit calculations to defined spans of time. | No |
set | Sets one or more fields used to identify distinct tracks. | Yes |
Examples
Run Detect Incidents
# Log in
import geoanalytics
geoanalytics.auth(username="myusername", password="mypassword")
# Imports
from geoanalytics.tools import DetectIncidents
from geoanalytics.sql import functions as ST
from pyspark.sql import functions as F
# Path to the Atlantic hurricanes data
data_path = r"https://sampleserver6.arcgisonline.com/arcgis/rest/services/" \
"Hurricanes/MapServer/0"
# Create an Atlantic hurricanes DataFrame
df = spark.read.format("feature-service").load(data_path) \
.st.set_time_fields("Date_Time")
# Run Detect Incidents to find where the windspeed of a hurricane is greater than
# or equal to 70 nautical miles per hour (knots)
result = DetectIncidents() \
.setTrackFields("EVENTID") \
.setStartConditionExpression(start_condition_expression="$feature.WINDSPEED >= 70") \
.setOutputMode("Incidents") \
.run(dataframe=df)
# Convert IncidentDuration from milliseconds to hours
result = result.withColumn("IncidentDuration_hours",
F.col("IncidentDuration") / (60 * 60 * 1000))
# Show the first 5 rows of the result DataFrame
result.filter(result["EVENTID"] == 'Alberto') \
.filter(result["IncidentStatus"] == 'OnGoing') \
.select("EVENTID", "IncidentStatus", "IncidentDuration","IncidentDuration_hours",
F.date_format("Date_Time", "yyyy-MM-dd").alias("Date_Time")) \
.sort("IncidentDuration_hours", "Date_Time", ascending=False).show(5, truncate=False)+-------+--------------+----------------+----------------------+----------+
|EVENTID|IncidentStatus|IncidentDuration|IncidentDuration_hours|Date_Time |
+-------+--------------+----------------+----------------------+----------+
|Alberto|OnGoing |302400000 |84.0 |2000-08-22|
|Alberto|OnGoing |280800000 |78.0 |2000-08-22|
|Alberto|OnGoing |259200000 |72.0 |2000-08-22|
|Alberto|OnGoing |237600000 |66.0 |2000-08-21|
|Alberto|OnGoing |237600000 |66.0 |2000-08-13|
+-------+--------------+----------------+----------------------+----------+
only showing top 5 rowsPlot results
# Create a world continents DataFrame for plotting
continents_path = "https://services.arcgis.com/P3ePLMYs2RVChkJx/ArcGIS/rest/services/" \
"World_Continents/FeatureServer/0"
continents_subset_df = spark.read.format("feature-service").load(continents_path) \
.where("""CONTINENT = 'North America' or CONTINENT = 'South America' or
CONTINENT = 'Africa' or CONTINENT = 'Europe'""")
# Plot the resulting incidents for hurricane Alberto with the USA continents data
continents_subset_plot = continents_subset_df.st.plot(facecolor="lightgreen",
edgecolors="black",
alpha=0.3,
figsize=(20,10),
basemap="light")
alberto_tracks_plot = df.where("EVENTID = 'Alberto'").st.plot(color="lightgrey",
edgecolors="darkgrey",
ax=continents_subset_plot)
result_plot = result.where("EVENTID = 'Alberto'").st.plot(cmap_values="IncidentStatus",
cmap="tab10",
is_categorical=True,
legend=True,
legend_kwds={"title": "Incident status",
"loc" : "upper left"},
ax=alberto_tracks_plot)
result_plot.set_title("Detected incidents for hurricane Alberto where windspeed was greater\n"
"than or equal to 70 nautical miles per hour (knots)", {'fontsize': 12})
result_plot.set_xlabel("X (Meters)")
result_plot.set_xlim(left=-20000000, right=8000000)
result_plot.set_ylabel("X (Meters)")
result_plot.set_ylim(bottom=-8000000, top=20000000);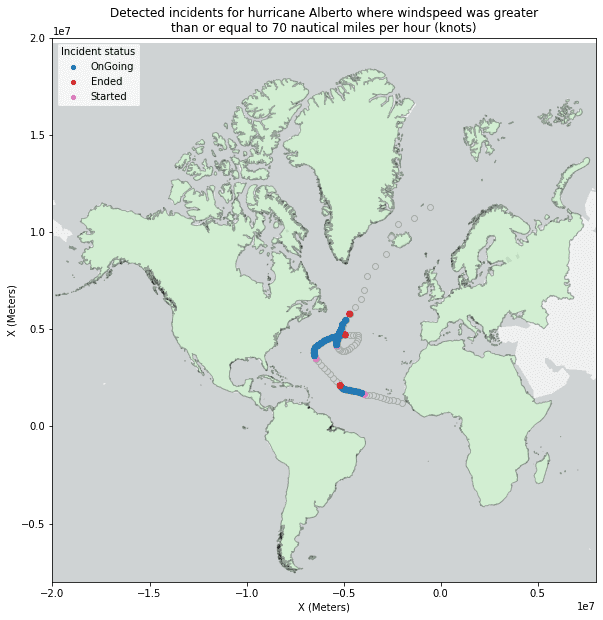
Version table
| Release | Notes |
|---|---|
1.0.0 | Python tool introduced |