Groups records that are within spatial or spatiotemporal proximity to each other.
Usage notes
-
The output result is a copy of the input with a new field named
group. The_id groupfield represents the grouping of records. Records with the same_id groupvalue are in the same group. The group numbers represent membership in a particular group and do not imply value. The group numbers may not be sequential or the same number in repeated runs of the tool._id -
The supported spatial relationships and input geometries are described in the following table:
Intersects Touches Geodesic Near Planar Near Point Linestring Polygon Full supportPartial supportNo support -
The spatial relationship definitions are outlined below.
| Overlay method | Description |
|---|---|
| Intersects | Records intersect when records or portions of records overlap. This is the default. |
| Touches | Records touch another record if they have an intersecting vertex, but the records do not overlap. |
| Geodesic Near | Records are near if a vertex or edge is within a given geodesic distance of another record. |
| Planar Near | Records are near if a vertex or edge is within a given planar distance of another record. |
-
When
'is specified withPlanar Near' set, it is required that the input DataFrame's geometry column is projected or the tool will fail. You can transform your data to a projected coordinate system by using ST_Transform.Spatial Relationship() -
The supported temporal relationships and temporal types are described in the following table:
Intersect Near None Instant Interval Full supportPartial supportNo support -
The temporal relationship definitions are outlined below.
| Temporal relationship method | Description |
|---|---|
| Intersects | When any part of a record's time overlaps another. |
| Near | Records are near one another if a record's time is within a given time distance of another record. |
-
You can specify any of the following combinations of relationships:
- A spatial relationship value
- A spatial relationship and a temporal relationship
- A spatial relationship and an attribute relationship
- A spatial relationship, temporal relationship, and an attribute relationship
-
Records are grouped when all specified relationships are met.
-
The attribute expression is a symmetric operation. The tool takes a single DataFrame that's compared against itself to group. Because of this, the input dataset is denoted as both
aandb, and all expressions should include both a and b. -
When specifying the attribute relationship you can create a Spark SQL expression or an Arcade expression. For example, to group all records where the column
Amounthas the same value do the following:- SQL:
a.Amount = b. Amount - Arcade:
$a.Amount == $b. Amount
- SQL:
Limitations
- Values will not be grouped across the anti-meridian.
Results
In addition to the original fields, the following additional fields are included:
| Field | Description |
|---|---|
group | The grouping of records. Records with the same group_id value are in the same group. The group numbers represent membership in a particular group and don't imply value. The group numbers may not be sequential or the same number in repeated runs of the tool. |
Performance notes
Improve the performance of Group By Proximity by doing one or more of the following:
-
Only analyze the records in your area of interest. You can pick the records of interest by using one of the following SQL functions:
- ST_Intersection—Clip to an area of interest represented by a polygon. This will modify your input records.
- ST_BboxIntersects—Select records that intersect an envelope.
- ST_EnvIntersects—Select records having an evelope that intersects the envelope of another geometry.
- ST_Intersects—Select records that intersect another dataset or area of intersect represented by a polygon.
- When using the planar or geodesic near, use a smaller distance.
- When using the spatial relationship parameter, the planar near option is faster than the geodesic near option.
- When using the temporal relationship parameter's near option, use a smaller temporal near distance.
Similar capabilities
Similar tools:
The following functions complete spatial overlay operations:
- ST_Aggr_Intersection
- ST_Aggr_union
- ST_Contains
- ST_Crosses
- ST_Difference
- ST_Dwithin
- ST_Equals
- ST_Intersection
- ST_Intersects
- ST_Overlaps
- ST_SymDifference
- ST_Touches
- ST_Union
- ST_Within
Syntax
For more details, go to the GeoAnalytics Engine API reference for group by proximity.
| Setter | Description | Required |
|---|---|---|
run(dataframe) | Runs the Group By Proximity tool using the provided DataFrame. | Yes |
set | Sets the type of spatial relationship to group by. | Yes |
set | Sets the type of temporal relationship to group by. | No |
set | Sets the attribute expression to group by. The expression type can be sql or Arcade. | No |
Examples
Run Group by Proximity
# Log in
import geoanalytics
geoanalytics.auth(username="myusername", password="mypassword")
# Imports
from geoanalytics.tools import GroupByProximity
from geoanalytics.sql import functions as ST
# Path to the USA rivers and streams data
usa_rivers_data_path = "https://services.arcgis.com/P3ePLMYs2RVChkJx/ArcGIS/rest" \
"/services/USA_Rivers_and_Streams/FeatureServer/0"
# Create an Oregon rivers DataFrame from the USA rivers and streams data
oregon_rivers_df = spark.read.format("feature-service") \
.load(usa_rivers_data_path) \
.where("State = 'OR'")
# Run the Group by Proximity tool to find intersecting rivers and streams
result = GroupByProximity() \
.setSpatialRelationship(spatial_relationship="Intersects") \
.run(dataframe=oregon_rivers_df)
# View the first 5 rows of the result DataFrame
result.select("State", "Name", "Region", "Feature", "Miles", "GROUP_ID") \
.sort("Miles", ascending=False).show(5)+-----+----------------+------+-------+------+--------+
|State| Name|Region|Feature| Miles|GROUP_ID|
+-----+----------------+------+-------+------+--------+
| OR|Willamette River| 17| Stream| 160.8| 2374|
| OR| John Day River| 17| Stream|122.73| 154|
| OR| Nehalem River| 17| Stream|107.92| 1819|
| OR| John Day River| 17| Stream|105.58| 154|
| OR| Deschutes River| 17| Stream|105.26| 1264|
+-----+----------------+------+-------+------+--------+
only showing top 5 rowsPlot results
# Plot the grouped results
# Create an Oregon boundary DataFrame and transform geometry to NAD 1983 StatePlane Oregon
usa_states_path = "https://services.arcgis.com/P3ePLMYs2RVChkJx/ArcGIS/rest" \
"/services/USA_State_Boundaries/FeatureServer/0"
oregon_df = spark.read.format("feature-service").load(usa_states_path) \
.where("STATE_NAME == 'Oregon'") \
.withColumn("shape", ST.transform("shape", 6558))
# Transform the grouped rivers' geometry to NAD 1983 StatePlane Oregon spatial reference
result = result.withColumn("shape", ST.transform("shape", 6558))
# Plot the result DataFrame with the Oregon data
oregon_plot = oregon_df.st.plot(facecolor="none", linewidth = 2, edgecolors="black",
figsize=(16,10), basemap="light")
result_plot = result.st.plot(geometry="shape" ,cmap_values="GROUP_ID",
is_categorical=True, cmap="tab20c",
ax=oregon_plot )
result_plot.set_title("Oregon rivers grouped by proximity")
result_plot.set_xlabel("X (Meters)")
result_plot.set_ylabel("Y (Meters)");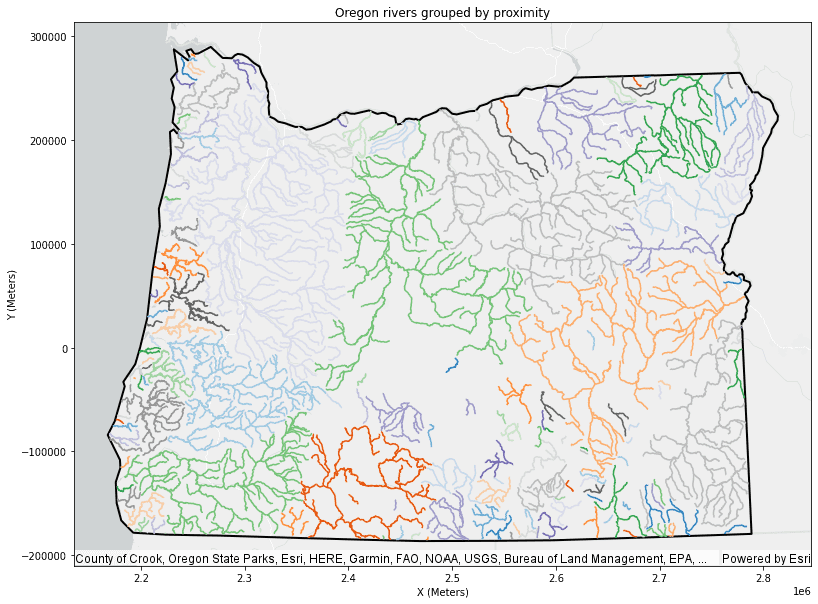
Version table
| Release | Notes |
|---|---|
1.0.0 | Python tool introduced |