Nearest Neighbors finds the given number of neighbors to a record in a DataFrame from records in another DataFrame. The records from the input DataFrames are matched based on closest proximity.

Usage notes
-
Nearest Neighbors supports point, line ,and polygon geometry types.
-
Nearest Neighbors supports two formats for the output layout in
set:Result Layout() -
Long—Each row represents a query record with a single nearest neighbor, and the columns include rank, distance between geometries of two records, and all fields from
queryand_dataframe data. The output is organized by stacking all paired records. This is the default._dataframe -
Wide—Each row represents a query record with all nearest neighbors, with the fields in
dataconsolidated into one column with distance to the query record. The columns include all fields from_dataframe queryand the information for each nearest neighbor._dataframe
-
-
Without setting the output layout, you can summarize all nearest neighbors in
datawith each record in_dataframe queryusing_dataframe add. Only those query records with neighbors will be maintained in the output DataFrame. For standard statistics, there are ten options: count, sum, mean, minimum, maximum, range, standard deviation, variance, first, and last. There are four options for string statistics: count, any, first, and last. To calculate first or last, time needs to be enabled on the input DataFrame.Summary Field() Learn more about enabling time on a DataFrame.
The tool returns the field statistics only when
addis used andSummary Field() setis not used. The tool will fail if both setters are used. By default, no statistics are calculated and the tool returns theResult Layout() long-format output. -
If you provide only one DataFrame, the DataFrame is used as both the
queryand the_dataframe data. In the output, each record will be joined with other nearby records, excluding itself. For example, if you are interested in finding the nearby cities for each city in the United States, you can provide the US-city DataFrame as the input DataFrame without specifying separate_dataframe queryand_Data Frame data._Data Frame -
The
setparameter determines how distances between data and query records are calculated. There are two distance methods available:Distance Method() -
Planar—Planar calculation is recommended for accurate analysis of small, local areas only. Planar calculation is the default when the input DataFrame is in a projected coordinate system.
-
Geodesic—Geodesic calculation is recommended for data in a coordinate system that is not appropriate for distance measurements (for example, Web Mercator) or for data that spans larger, global areas. Geodesic calculation is the default when the input DataFrame is in a geographic coordinate system.
If the
queryand_Data Frame datahave different coordinate systems, analysis will be completed in the coordinate system of the_Data Frame query. To learn more about the difference between planar and geodesic calculations see Coordinate systems and transformations._Data Frame -
-
If either DataFrame has a spatial reference, the other DataFrame must also have a spatial reference or the tool will fail. If both input DataFrames have no spatial references, Nearest Neighbors can be used to calculate the planar distance and find neighbors with the assumption that the search distance and output distance have the same unit as the input coordinates. In this case, the distance method should be set to
planar, and the search distance unit should be set toNone. -
If there are multiple nearest neighbors with an equal distance to the query record, nearest neighbor will break ties by randomly selecting one or more records from the equidistant neighbors to ensure the specified number of closest neighbors. For example, if you are interested in finding two nearest neighbors when there are three records that are equidistant from the query record, two of the three records will be randomly selected and returned in the output.
-
Set a search distance to exclude neighbors further away than the search distance. This can result in fewer neighbors returned than the specified number of neighbors. For example, if you are interested in finding three nearest neighbors within a specified search distance when there are two records within the distance, only the two neighbors will be returned in the output.
-
When Nearest Neighbors finds fewer neighbors in the
datathan the specified number of neighbors, it will return_dataframe Nullfor no neighbors in awide-format output, or only return rows that have a matched neighbor in along-format output.
Results
The format of the output DataFrame differs depending on the output layout type and whether to summarize statistics.
The two options for the layout types are long and wide. When the layout is not set and the summary fields are
specified, the output DataFrame returns the summary statistics as the output.
Long-format layout
-
The following fields are included in the output DataFrame with the long-format layout:
- All fields from the query DataFrame
- All fields from the data DataFrame
In addition, the following fields are included in the output records:
| Field | Description |
|---|---|
near | The rank of the nearest neighbors. The rank is given according to ascending order distance. |
near | The distance between the record in the query to the identified nearest neighbor from the data. |
Wide-format layout
-
The following fields are included in the output DataFrame with the wide-format layout:
- All fields from the query DataFrame
-
In addition, there is one column for each near record with the sub-fields in the output DataFrame:
near—The distance to the query record_distance - All fields from the data DataFrame
For example, if the number of neighbors is 3, three new fields will be appended to the result dataframe, near1, near2,
and near3. Each of the three fields include near and all fields from the data DataFrame.
Summary-statistics layout
If set is not used and the nearest neighbors in the data are
summarized for each query record using add, the tool returns all fields from
query. In addition, the following fields are included in the output records:
| Field | Description |
|---|---|
<statistic | Specified statistics will each create a field named using the following format: statistic_fieldname. For example, the maximum and standard deviation of the size field is MAX_size and SD_size. |
Performance notes
Improve the performance of Nearest Neighbors by doing one or more of the following:
-
Only analyze the records in your area of interest. You can pick the records of interest by using one of the following SQL functions:
- ST_Intersection—Clip to an area of interest represented by a polygon. This will modify your input records.
- ST_BboxIntersects—Select records that intersect an envelope.
- ST_EnvIntersects—Select records having an evelope that intersects the envelope of another geometry.
- ST_Intersects—Select records that intersect another dataset or area of intersect represented by a polygon.
- Use the planar distance calculation method instead of geodesic.
- Set a search distance with
set, especially when using the geodesic distance calculation method.Search Distance() - If the data is in geographic coordinate system but for small, local areas, project it to a local coordinate system, and then choose planar for distance calculation. You can transform your data to a projected coordinate system by using ST_Transform.
- For geodesic calculation, if the polyline or polygon geometries are small but spaced far apart, consider using ST_Centroid to get the centroid representation of the input geometry before running Nearest Neighbors.
- For geodesic calculation, consider generalizing the input polyline or polygon geometries using ST_Generalize.
- Use smaller values for
setandSearch Distance() set.Num Neighbors()
Similar capabilities
Syntax
For more details, go to the GeoAnalytics Engine API reference for nearest neighbors.
| Setter | Description | Required |
|---|---|---|
run(query | Runs the Nearest Neighbors tool using the provided DataFrames. query is a DataFrame containing geometries whose nearest neighbors will be found, and data is a DataFrame containing the neighbor candidates. | Yes |
set | Sets the number of neighbors (k) to find that are nearest to the query record. | Yes |
set | Sets the method used to calculate distances between data and query records. There are two methods to choose from: ' or '. See Usage notes for the default option. | No |
set | Sets a distance bound within which to search for nearest neighbors. Choose from ', ', ', ', ', ', or None. | No |
set | Sets the output unit of the near distances for the result DataFrame. Choose from ' (default), ', ', ', ', or '. | No |
set | Sets the layout format for the result DataFrame. Choose from 'long' format (default) or 'wide' format. | No |
add | Adds a summary statistic of a field in the data DataFrame to the result DataFrame. Statistics for numeric fields include Count, Sum, Mean, Max, Min, Range, Stddev, Var, First, Last, or Any. There are four options for string statistics: Count, Any, First, and Last. | No |
Examples
Run Nearest Neighbors
# Log in
import geoanalytics
geoanalytics.auth(username="myusername", password="mypassword")
# Imports
from geoanalytics.tools import NearestNeighbors, Clip
from geoanalytics.sql import functions as ST
from pyspark.sql import functions as F
# Path to the USA parks, public schools and county boundary data
parks_data_path = "https://services.arcgis.com/P3ePLMYs2RVChkJx/arcgis/rest/services/USA_Parks/FeatureServer/0"
schools_data_path = "https://services1.arcgis.com/Ua5sjt3LWTPigjyD/arcgis/rest/services/Public_School_Location_201819/FeatureServer/0"
counties_data_path = "https://services.arcgis.com/P3ePLMYs2RVChkJx/arcgis/rest/services/USA_Counties_Generalized_Boundaries/FeatureServer/0"
# Create DataFrames for park data and school data in Los Angeles County
la_df = spark.read.format("feature-service").load(counties_data_path) \
.where("NAME == 'Los Angeles County'") \
.withColumn("shape", ST.transform("shape", 6423))
schools_df = spark.read.format("feature-service").load(schools_data_path) \
.withColumn("shape", ST.transform("shape", 6423))
parks_df = spark.read.format("feature-service").load(parks_data_path) \
.withColumn("shape", ST.transform("shape", 6423))
schools_la = Clip().run(schools_df, la_df).select("NCESSCH","NAME","STREET", "CITY", F.col("clip_geometry").alias("shape"))
parks_la = Clip().run(parks_df, la_df).select("FID","NAME","SQMI","FEATTYPE",F.col("clip_geometry").alias("shape"))
# Run Nearest Neighbors tool to identify the 4 closest parks near each school within 1 kilometer
print("This is the long-format layout for the output:")
result_long = NearestNeighbors() \
.setNumNeighbors(4) \
.setSearchDistance(1, "Kilometer") \
.setResultLayout("long") \
.run(schools_la, parks_la)
result_long.where("NCESSCH == '062271003393'").sort("near_rank").show()
print("This is the wide-format layout for the output:")
result_wide = NearestNeighbors() \
.setNumNeighbors(4) \
.setSearchDistance(1, "Kilometer") \
.setResultLayout("wide") \
.run(schools_la, parks_la)
result_wide.where("NCESSCH == '062271003393'").show()
print("To summarize the nearest neighbors with each query record:")
result_summary = NearestNeighbors() \
.setNumNeighbors(4) \
.setSearchDistance(1, "Kilometer") \
.addSummaryField("NAME", "count", "count") \
.addSummaryField("SQMI", "MEAN") \
.run(schools_la, parks_la)
result_summary.where("NCESSCH == '062271003393'").show()This is the long-format layout for the output:
+------------+--------------------+----------------+-----------+--------------------+---------+-----------------+----+--------------------+----+----------+--------------------+
| NCESSCH| NAME| STREET| CITY| shape|near_rank| near_distance| FID| NAME1|SQMI| FEATTYPE| shape1|
+------------+--------------------+----------------+-----------+--------------------+---------+-----------------+----+--------------------+----+----------+--------------------+
|062271003393|Tenth Street Elem...|1000 Grattan St.|Los Angeles|{"x":1974761.5562...| 1|561.1051650746004|7182| Hope and Peace Park| 0.0|Local park|{"rings":[[[19744...|
|062271003393|Tenth Street Elem...|1000 Grattan St.|Los Angeles|{"x":1974761.5562...| 2|653.9133604877863|7160|Alvarado Terrace ...| 0.0|Local park|{"rings":[[[19740...|
|062271003393|Tenth Street Elem...|1000 Grattan St.|Los Angeles|{"x":1974761.5562...| 3| 969.461870743635|7159| MacArthur Park|0.06|Local park|{"rings":[[[19744...|
+------------+--------------------+----------------+-----------+--------------------+---------+-----------------+----+--------------------+----+----------+--------------------+
This is the wide-format layout for the output:
+------------+--------------------+----------------+-----------+--------------------+--------------------+--------------------+--------------------+-----+
| NCESSCH| NAME| STREET| CITY| shape| near1| near2| near3|near4|
+------------+--------------------+----------------+-----------+--------------------+--------------------+--------------------+--------------------+-----+
|062271003393|Tenth Street Elem...|1000 Grattan St.|Los Angeles|{"x":1974761.5562...|{561.105165074600...|{653.913360487786...|{969.461870743635...| NULL|
+------------+--------------------+----------------+-----------+--------------------+--------------------+--------------------+--------------------+-----+
To summarize the nearest neighbors with each query record:
+------------+--------------------+----------------+-----------+--------------------+-----+---------+
| NCESSCH| NAME| STREET| CITY| shape|count|MEAN_SQMI|
+------------+--------------------+----------------+-----------+--------------------+-----+---------+
|062271003393|Tenth Street Elem...|1000 Grattan St.|Los Angeles|{"x":1974761.5562...| 3.0| 0.02|
+------------+--------------------+----------------+-----------+--------------------+-----+---------+Plot results
result_sample = result_long.where("NAME = 'Rise Kohyang Middle'") \
.withColumn("buffer", ST.buffer("shape", 1000))
school_area = result_sample.st.plot(geometry="buffer",
facecolor="none",
edgecolor="lightblue",
figsize=(16, 10))
school_area.set(xlim=(1.9715e6, 1.9755e6), ylim=(561000, 563750))
school_plot = result_sample.st.plot(geometry="shape", legend=True, label='Rise Kohyang Middle School', ax=school_area)
result_plot = result_sample.st.plot(geometry="shape1",
is_categorical=True,
cmap_values="NAME1",
cmap="Greens",
basemap="light",
legend=True,
label='Parks',
ax=school_area)
result_plot.set_title("Searching for four nearest parks around Rise Kohyang Middle School within 1 Km search distance")
result_plot.set_xlabel("X (Meters)")
result_plot.set_ylabel("Y (Meters)")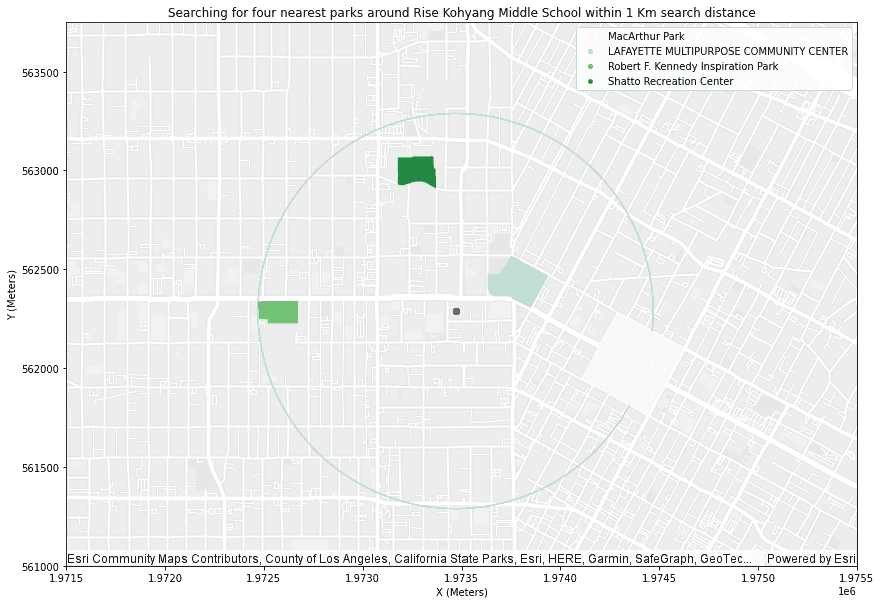
Version table
| Release | Notes |
|---|---|
1.1.0 | Python tool introduced |
1.2.0 | Added support for geodesic distance method with a distance bound. |
1.4.0 | Added support for geodesic calculation without a distance bound and summarizing statistics. |