TRK_Aggr_CreateTrack operates on a grouped DataFrame and creates tracks using the points in each group, where each point represents an entity's observed location at an instant. The output tracks are linestrings that represent the shortest path between each observation. Each vertex in the linestring has a timestamp (stored as the M-value) and the vertices are ordered sequentially.
Tracks are usually created after grouping points by one or more fields that uniquely identify each entity. For example, to create tracks that represent individual taxi trips, you might group point observations of taxis by a trip ID field. To create tracks that represent entire taxi shifts, you might group by both a driver ID field and a date field. You can group your DataFrame using DataFrame.groupBy() or with a GROUP BY clause in a SQL statement.
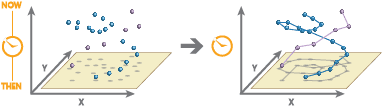
Track M-values represent an instant in time and are stored in units of seconds from epoch. M-values in the input points will be ignored and not included in the result linestring. Z-values will be included as Z-values in the result linestring.
For more information on using tracks in GeoAnalytics Engine, see the core concept topic on tracks.
| Function | Syntax |
|---|---|
| Python | aggr |
| SQL | TRK |
| Scala | aggr |
For more details, go to the GeoAnalytics Engine API reference for aggr_create_track.
Python and SQL Examples
from geoanalytics.tracks import functions as TRK
from geoanalytics.sql import functions as ST
from pyspark.sql import functions as F
data = [
("POINT (-117.22 33.91)", 1, "2021-10-05 10:31:02"),
("POINT (-117.27 34.05)", 1, "2021-10-05 10:30:10"),
("POINT (-116.96 33.64)", 1, "2021-10-05 10:32:12"),
("POINT (-116.66 33.71)", 1, "2021-10-05 10:33:26"),
("POINT (-116.89 33.96)", 2, "2021-10-06 20:04:55"),
("POINT (-116.71 34.01)", 2, "2021-10-06 20:06:22"),
("POINT (-117.05 34.22)", 2, "2021-10-06 20:08:39"),
("POINT (-116.66 34.08)", 2, "2021-10-06 20:07:41")
]
df = spark.createDataFrame(data, ["wkt", "id", "datetime_str"]) \
.withColumn("point", ST.point_from_text("wkt", srid=4326)) \
.withColumn("timestamp", F.to_timestamp("datetime_str"))
agg_df = df.groupBy("id").agg(TRK.aggr_create_track("point", "timestamp").alias("track"))
ax = df.st.plot("point", facecolor="none", edgecolor="red", figsize=(15, 8))
agg_df.st.plot("track", ax=ax, facecolor="none", edgecolor="blue")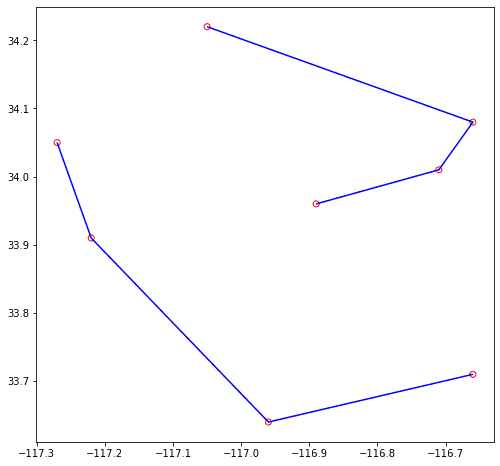
Scala Example
import com.esri.geoanalytics.sql.{functions => ST}
import com.esri.geoanalytics.sql.{trackFunctions => TRK}
import org.apache.spark.sql.{functions => F}
import java.sql.Timestamp
case class pointRow(pointWkt: String, id: Int, timestamp: Timestamp)
val data = Seq(pointRow("POINT (-117.22 33.91)", 1, Timestamp.valueOf("2021-10-05 10:31:02")),
pointRow("POINT (-117.27 34.05)", 1, Timestamp.valueOf("2021-10-05 10:30:10")),
pointRow("POINT (-116.96 33.64)", 1, Timestamp.valueOf("2021-10-05 10:32:12")),
pointRow("POINT (-116.66 33.71)", 1, Timestamp.valueOf("2021-10-05 10:33:26")),
pointRow("POINT (-116.89 33.96)", 2, Timestamp.valueOf("2021-10-06 20:04:55")),
pointRow("POINT (-116.71 34.01)", 2, Timestamp.valueOf("2021-10-06 20:06:22")),
pointRow("POINT (-117.05 34.22)", 2, Timestamp.valueOf("2021-10-06 20:08:39")),
pointRow("POINT (-116.66 34.08)", 2, Timestamp.valueOf("2021-10-06 20:07:41")))
val points = spark.createDataFrame(data)
.withColumn("point", ST.pointFromText($"pointWkt", F.lit(4326)))
val tracks = points.groupBy("id").agg(TRK.aggrCreateTrack($"point", $"timestamp").alias("track"))
tracks.show(truncate = false)+---+-------------------------------------------------------------------------------------------------------------------------------------------------+
|id |track |
+---+-------------------------------------------------------------------------------------------------------------------------------------------------+
|1 |{"hasM":true,"paths":[[[-117.27,34.05,1.63345501e9],[-117.22,33.91,1.633455062e9],[-116.96,33.64,1.633455132e9],[-116.66,33.71,1.633455206e9]]]} |
|2 |{"hasM":true,"paths":[[[-116.89,33.96,1.633575895e9],[-116.71,34.01,1.633575982e9],[-116.66,34.08,1.633576061e9],[-117.05,34.22,1.633576119e9]]]}|
+---+-------------------------------------------------------------------------------------------------------------------------------------------------+Version table
| Release | Notes |
|---|---|
1.4.0 | Python and SQL functions introduced |
1.5.0 | Scala function introduced |