TRK_SplitByDuration takes a track column and a duration and returns an array of tracks. The result array contains the input track split into segments with each segment no longer than the specified duration.
The duration can be defined using ST_CreateDuration or with a tuple
containing a number and a unit string (e.g., (5, "minutes")).
Tracks are linestrings that represent the change in an entity's location over time. Each vertex in the linestring has a timestamp (stored as the M-value) and the vertices are ordered sequentially.
For more information on using tracks in GeoAnalytics Engine, see the core concept topic on tracks.
| Function | Syntax |
|---|---|
| Python | split |
| SQL | TRK |
| Scala | split |
For more details, go to the GeoAnalytics Engine API reference for split_by_duration.
Python and SQL Examples
from geoanalytics.sql import functions as ST
from geoanalytics.tracks import functions as TRK
from pyspark.sql import functions as F
data = [
("LINESTRING M (-117.27 34.05 1633455010, -117.22 33.91 1633456062, -116.96 33.64 1633457132)",),
("LINESTRING M (-116.89 33.96 1633575895, -116.71 34.01 1633576982, -116.66 34.08 1633577061)",),
("LINESTRING M (-116.24 33.88 1633575234, -116.33 34.02 1633576336)",)
]
df = spark.createDataFrame(data, ["wkt"]).withColumn("track", ST.line_from_text("wkt", srid=4326))
result = df.withColumn("split_by_duration", TRK.split_by_duration("track", (10, "minutes")))
result.select(F.explode("split_by_duration"), F.monotonically_increasing_id().alias("id")) \
.st.plot(is_categorical=True, cmap_values="id", cmap="prism", linewidths=10, figsize=(15, 8))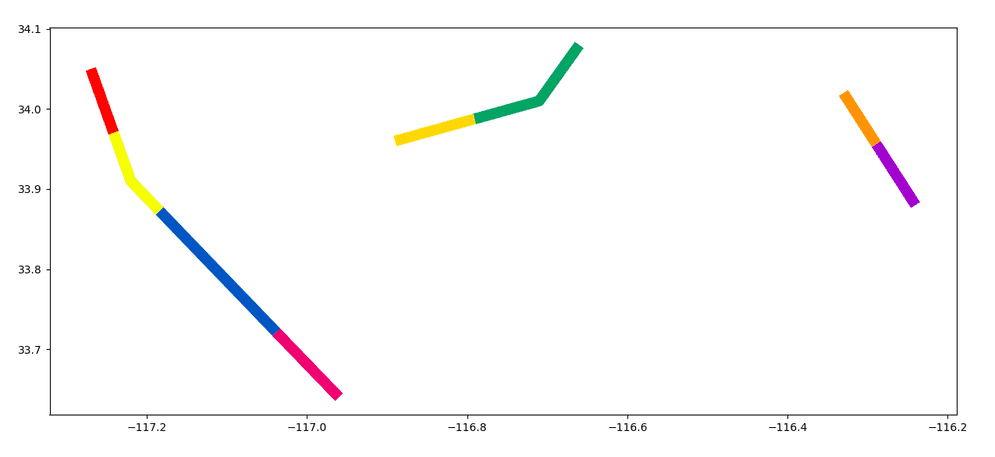
Scala Example
import com.esri.geoanalytics.sql.{functions => ST}
import com.esri.geoanalytics.sql.{trackFunctions => TRK}
import org.apache.spark.sql.{functions => F}
case class lineRow(lineWkt: String)
val data = Seq(lineRow("LINESTRING M (-117.27 34.05 1633455010, -117.22 33.91 1633456062, -116.96 33.64 1633457132)"),
lineRow("LINESTRING M (-116.89 33.96 1633575895, -116.71 34.01 1633576982, -116.66 34.08 1633577061)"),
lineRow("LINESTRING M (-116.24 33.88 1633575234, -116.33 34.02 1633576336)"))
val df = spark.createDataFrame(data)
.withColumn("track", ST.lineFromText($"lineWkt", F.lit(4326)))
.withColumn("split_by_duration", TRK.splitByDuration($"track", F.lit(struct(F.lit(10), F.lit("minutes")))))
.withColumn("result_tracks", F.explode($"split_by_duration"))
df.select("result_tracks").show(5, truncate = false)+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|result_tracks |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|{"hasM":true,"paths":[[[-117.27,34.05,1.63345501e9],[-117.24148288973383,33.97015209125475,1.63345561e9]]]} |
|{"hasM":true,"paths":[[[-117.24148288973383,33.97015209125475,1.63345561e9],[-117.22,33.91,1.633456062e9],[-117.18403738317757,33.872654205607475,1.63345621e9]]]}|
|{"hasM":true,"paths":[[[-117.18403738317757,33.872654205607475,1.63345621e9],[-117.0382429906542,33.7212523364486,1.63345681e9]]]} |
|{"hasM":true,"paths":[[[-117.0382429906542,33.7212523364486,1.63345681e9],[-116.96,33.64,1.633457132e9]]]} |
|{"hasM":true,"paths":[[[-116.89,33.96,1.633575895e9],[-116.79064397424102,33.987598896044155,1.633576495e9]]]} |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
only showing top 5 rowsVersion table
| Release | Notes |
|---|---|
1.4.0 | Python and SQL functions introduced |
1.5.0 | Scala function introduced |