Introduction
Geospatial data is not only available in the form of maps and feature/imagery layers, but also in form of unstructured text.
What is unstructured text?
Unstructured text is written content that lacks structure and cannot readily be indexed or mapped onto standard database fields. It is often user-generated information such as emails, instant messages, news articles, documents or social media postings.
These unstructured documents can contain location information which makes them geospatial information. Mapping information from such documents could be of a great value. In this guide, we will explore how to achieve this objective with arcgis.learn.
What is Named Entity Recognition?
Named Entity Recognition is a branch of information extraction. This is used to identify entities such as "Organizations", "Person", "Date", "Country", etc. that are present in the text.

Figure1: Example of named entities such as PERSON, ORG & DATE in unstructured text. Source:
Explosion AI blogPrerequisites
-
Data preparation and model training workflows for entity extraction using
arcgis.learnis based on spaCy & Hugging Face Transformers libraries. A user can choose an appropriate backbone to train the model. -
Refer to the section Install deep learning dependencies of arcgis.learn module for detailed explanation about deep learning dependencies.
-
Labeled data: For
EntityRecognizerto learn, it needs to see examples that have been labeled for all the custom categories that the model is expected to extract. Head to the Data preparation section to see the supported formats for training data. -
If you wish to try this workflow, you can find a sample notebook along with the necessary labeled training and test datasets over here.
EntityRecognizer Model Basics
EntityRecognizer model in arcgis.learn can be created with either Hugging Face Transformers or with spaCy's EntityRecognizer architecture.
Transformers Overview
Transformers in NLP are novel architectures that aims to solve sequence-to-sequence tasks while handling long-range dependencies with ease. The transformers are the most latest and advanced models that give state of the art results for a wide range of tasks such as text/sequence classification, named entity recognition (ner), question answering, machine translation, text summarization, text generation etc.
The Hugging Face Transformers library provides transformer models like BERT, RoBERTa, XLM, DistilBert, XLNet etc., for Natural Language Understanding (NLU) with over 32+ pretrained models in 100+ languages.
A transformer consists of an encoding component, a decoding component, and connections between them.
- The Encoding component is a stack of encoders (the paper stacks six of them on top of each other).
- The Decoding component is a stack of decoders of the same number.
The encoders are all identical in structure (yet they do not share weights). Each one is broken down into two sub-layers:
-
Self-Attention Layer
-
Say the following sentence is an input sentence we want to translate:
The animal didn't cross the street because it was too tired
What does "it" in this sentence refer to? Is it referring to the street or to the animal? It's a simple question to a human, but not as simple to an algorithm. When the model is processing the word "it", self-attention allow the model to associate "it" with "animal".
-
-
Feed Forward Layer - The outputs of the self-attention layer are fed to a feed-forward neural network.
The decoder has both those layers (self-attention & feed forward layer), but between them is an attention layer (sometimes called encoder-decoder attention) that helps the decoder focus on relevant parts of the input sentence.
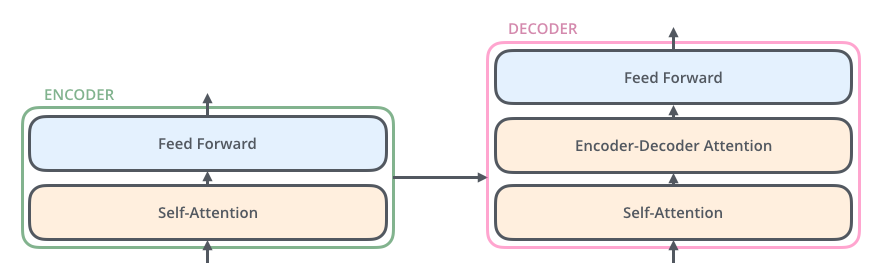
Figure3: Depicting different layers and their interaction in Transformer encoder & decoder components
To get a more detail explanation on different forms of attention visit this page. Also there is a great blog post on Visualizing attention in machine translation model that can help in understanding the attention mechanism in a better way.
How to choose an appropriate transformer backbone for your dataset?
This page mentions different trasformer architectures [3]. Not every architecture can be used to train a Named Entity Recognition model. As of now, there are around 12 different architectures which can be used to perform Named Entity Recognition (NER) task. These are BERT[4], RoBERTa, DistilBERT, ALBERT, FlauBERT, CamemBERT, XLNet, XLM, XLM-RoBERTa, ELECTRA, Longformer and MobileBERT.
Some consideration has to be made to pick the right transformer architecture for the problem at hand.
- Some models like
BERT,RoBERTa,XLNET,XLM-RoBERTaare highly accurate but at the same time are larger in size. Generating inference from these models is somewhat slow. - If one wishes to sacrifice a little accuracy over a high inferencing and training speed one can go with
DistilBERT. - If the model size is a constraint, then one can either choose
ALBERTorMobileBERT. Remember the model performance will not be as great compared to models likeBERT,RoBERTa,XLNET, etc. - If you have a dataset in the French language one can choose from
FlauBERTorCamemBERTas these language model are trained on French text. - When dealing with long sentences/sequences in training data one can choose from
XLNET,Longformer,Bart. - Some models like
XLM,XLM-RoBERTaare multi-lingual models i.e. models trained on multiple languages. If your dataset consists of text in multiple languages you can chooses models mentioned in the above link.- The model sizes of these transformer architectures are very large (in GBs).
- They require large memory to fine tune on a particular dataset.
- Due to the large size of these models, inferencing a fined-tuned model will be somewhat slow on CPU.
Entity recognition with spaCy
This Model works on the Embed > Encode > Attend > Predict deep learning framework [1].
- Embed: This is the process of turning text or sparse vectors into dense word embeddings. These embeddings are much easier to work with than other representations and do an excellent job of capturing semantic information. This is achieved by extracting word features using feature hashing[2] followed by a Multilayer Perceptron. A video description of this workflow can be found here.

- Encode : This is the process of encoding context into a word vector. This is done using Residual Trigram CNNs.

- Attend : In this model attention refers to manually extracting features from the encoded tokens. This step has a similar effect as the attention mechanism.

- Predict : The final step in the model is making a prediction given the input text. Here the vector from the attention layer is passed to a Multilayer Perceptron to output the entity label ID.

Figure2: Different components of entity recognition workflow in spaCy based on
Explosion AI blog on deep learning formula for NLP modelsData preparation
-
Entity Recognizer can consume labeled training data in four different formats (csv, ner_json, IOB & BILUO).
-
Example structure for csv format:
- Columns:
- The CSV should include a
textcolumn. - Additional columns will be named according to the name entity types (e.g.,
Address,Crime,Crime_datetime, etc.).
- The CSV should include a
- Rows:
-
Each row will contain the full text in the
textcolumn. -
The other columns will contain the specific entity values corresponding to the column name.

-
- Columns:
-
Example structure for ner_json format:
- Text :
"Sir Chandrashekhara Venkata Raman was born in India" - JSON formatted training data: {"text": "Sir Chandrashekhara Venkata Raman was born in India.", "labels": [[0, 33, "Person"], [46, 51, "Country"]]}
- Text :
-
Example structure for IOB format:
- Text:
"Sir Chandrashekhara Venkata Raman was born in India." - IOB formatted training data:
- Row in tokens.csv:
'Sir', 'Chandrashekhara', 'Venkata', 'Raman', 'was', 'born', 'in', 'India', '.' - Row in tags.csv:
'B-Person', 'I-Person', 'I-Person', 'I-Person', 'O', 'O', 'O', 'B-Country', 'O'
- Row in tokens.csv:
- Text:
-
Example structure for BILUO format:
- Text:
"Sir Chandrashekhara Venkata Raman was born in India." - LBIOU formatted training data:
- Row in tokens.csv:
'Sir', 'Chandrashekhara', 'Venkata', 'Raman', 'was', 'born', 'in', 'India', '.' - Row in tags.csv:
'B-Person', 'I-Person', 'I-Person', 'L-Person', 'O', 'O', 'O', 'U-Country', 'O'
- Row in tokens.csv:
- Text:
Data preparation involves splitting the data into training and validation sets, creating the necessary data structures for loading data into the model and so on. The prepare_data() function can directly read the training samples in one of the above specified formats and automate the entire process. While calling this function, user has to provide the following arguments:
- path - Path to data directory for data in IOB or BILUO format or the path to the json file if labelled training data is in JSON format.
- dataset_type - Input format for you labelled training data (one of IOB, BILUO, ner_json).
- class_mapping - Entity defined in 'address_tag' will be treated as location (addresses or geographical locations).
- encoding - The encoding to read the csv/json file (default is set to 'UTF-8').
- text_columns - Provide the
textcolumn name when using csv format data.
import os
import spacy
import random
from arcgis.learn import prepare_textdata
from arcgis.learn.text import EntityRecognizerjson_path = os.path.join('data', 'EntityRecognizer', 'labelled_crime_reports.csv')data=prepare_textdata(path=json_path, task="entity_recognition", dataset_type='csv', text_columns="text", class_mapping={'address_tag':'Address'})The show_batch() method can be used to visualize the training samples, along with labels.
data.show_batch()| text | Address | Crime | Crime_datetime | Reported_date | Reported_time | Reporting_officer | Weapon | |
|---|---|---|---|---|---|---|---|---|
| 0 | One victim was punched several times in the fa... | [300 block of Parkwood Lane] | [robbed, punched, pushed down] | [Monday night] | [01/19/2016] | [10:00 AM] | [PIO Joel Despain] | |
| 1 | A MPD detective noticed a person slumped over ... | [Culver's, 1325 Northport Dr., Sherman Ave.] | [01/24/2019] | [9:06 AM] | [PIO Joel Despain] | |||
| 2 | The MPD is seeking citizen help in locating a ... | [W. Badger Rd] | [missing] | [9:00 p.m. Monday night] | [08/23/2017] | [1:04 PM] | [PIO Joel Despain] | |
| 3 | A City of Madison Parking Enforcement Officer ... | [Riley's Wines of the World, 1400 Block of Mor... | [stolen, stolen] | [June 21, 2016] | [06/24/2016] | [6:28 PM] | [Sgt. Nicholas Ellis] | |
| 4 | A dispute over a State St. panhandling spot re... | [500 block of State St.] | [dispute, punched, battery] | [03/20/2017] | [11:48 AM] | [PIO Joel Despain] | ||
| 5 | A Madison man reported being robbed of cash an... | [N. Marquette St] | [robbed] | [last night] | [09/14/2016] | [10:34 AM] | [PIO Joel Despain] | [handgun] |
| 6 | On 6/10/18 at 1:50 am the Madison Police Depar... | [2000 block of Post Rd] | [6/10/18 at 1:50 am] | [3:26 AM] | [Lt. Jamar Gary] | |||
| 7 | A concerned caller told police a driver fired ... | [intersection of Wisconsin Ave. and E. Gorham ... | [ired some type of weapon, weapon's violation] | [Fourth of July, around 11:00 p.m., 8:00 p.m. ... | [10:55 AM] | [PIO Joel Despain] | [flare gun] |
EntityRecognizer model
EntityRecognizer model in arcgis.learn can be used with spaCy's EntityRecognizer backbone or with Hugging Face Transformers backbones. The model training and inferencing workflow is similar to computer vision models in arcgis.learn.
Run the command below to see what backbones are supported for the entity recognition task.
print(EntityRecognizer.supported_backbones)['spacy', 'BERT', 'RoBERTa', 'DistilBERT', 'ALBERT', 'CamemBERT', 'MobileBERT', 'XLNet', 'XLM', 'XLM-RoBERTa', 'FlauBERT', 'ELECTRA', 'Longformer', 'Funnel', 'LLM']
Apart from the 'spacy' backbone listed above, rest all are transformer backbones. The Hugging Face Transformer library provides a wide variety of models for each of the backbone listed above. To see the full list visit this link.
- The call to
available_backbone_models()method will list out only few of the available models for each backbone. - This list is not exhaustive and only contain subset of the models listed in the link above. This function is created to give a general idea to the user about the available models for a given backbone.
- That being said, the
EntityRecognizerclass supports any model from the 12 available transformer backbones and spaCy backbone. - Some of the Transformer models are quite large due to the high number of training parameters or large number of intermediate layers. Thus, large models will have large CPU/GPU memory requirements.
print(EntityRecognizer.available_backbone_models("roberta"))('roberta-base', 'roberta-large', 'distilroberta-base')
print(EntityRecognizer.available_backbone_models("spacy"))('spacy',)
Construct the EntityRecognizer object by passing the data and the backbone you have chosen.
ner = EntityRecognizer(data, backbone='spacy')Model training
Finding optimum learning rate
In machine learning, the learning rate is a tuning parameter that determines the step size at each iteration while moving towards a minimum of a loss function, it also represents the speed at which a machine learning model "learns"
- If the learning rate is low, then model training will take a lot of time because steps towards the minimum of the loss function are tiny.
- If the learning rate is high, then training may not converge or even diverge. Weight changes can be so big that the optimizer overshoots the minimum and makes the loss worse.
To find the optimum learning rate for our model, we will call the lr_find() method of the model.
Note
- A user is not required to call the
lr_find()method separately. Iflrargument is not provided while calling thefit()method thenlr_find()method is internally called by thefit()method to find the optimal learning rate.
lr_val = ner.lr_find()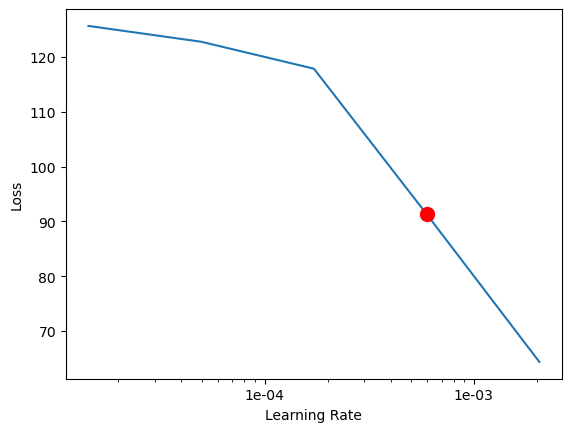
Training the model is an iterative process. We can train the model using its fit() method till the validation loss (or error rate) continues to go down with each training pass also known as epoch. This is indicative of the model learning the task.
ner.fit(epochs=10, lr=lr_val)| epoch | losses | val_loss | precision_score | recall_score | f1_score | time |
|---|---|---|---|---|---|---|
| 0 | 9.89 | 16.86 | 0.52 | 0.31 | 0.38 | 00:00:05 |
| 1 | 9.6 | 7.23 | 0.57 | 0.36 | 0.44 | 00:00:05 |
| 2 | 8.96 | 7.37 | 0.49 | 0.24 | 0.32 | 00:00:05 |
| 3 | 9.26 | 5.12 | 0.57 | 0.45 | 0.51 | 00:00:05 |
| 4 | 7.16 | 4.18 | 0.6 | 0.55 | 0.57 | 00:00:05 |
| 5 | 6.79 | 3.51 | 0.73 | 0.68 | 0.7 | 00:00:05 |
| 6 | 6.45 | 3.28 | 0.73 | 0.58 | 0.65 | 00:00:05 |
| 7 | 6.61 | 2.59 | 0.76 | 0.62 | 0.68 | 00:00:05 |
| 8 | 6.32 | 2.21 | 0.85 | 0.86 | 0.86 | 00:00:05 |
| 9 | 6.0 | 1.76 | 0.8 | 0.69 | 0.75 | 00:00:05 |
Evaluate model performance
Important metrics to look at while measuring the performance of the EntityRecognizer model are Precision, Recall & F-measures [7].
Here is a brief description of them:
- Precision - Precision talks about how precise/accurate your model is. Out of those predicted positive, how many of them are actual positive.
- Recall - Recall is the ability of the classifier to find all the positive samples.
- F1 - F1 can be interpreted as a weighted harmonic mean of the precision and recall. To learn more about these metrics one can visit the following link - Precision, Recall & F1 score.
To find precision, recall & f1 scores per label/class we will call the model's metrics_per_label() method.
ner.metrics_per_label()| Precision_score | Recall_score | F1_score | |
|---|---|---|---|
| Crime | 0.42 | 0.36 | 0.38 |
| Crime_datetime | 0.83 | 0.77 | 0.80 |
| Address | 0.95 | 0.72 | 0.82 |
| Weapon | 0.88 | 0.54 | 0.67 |
| Reported_time | 1.00 | 1.00 | 1.00 |
| Reporting_officer | 1.00 | 1.00 | 1.00 |
| Reported_date | 0.92 | 0.73 | 0.81 |
Validate results
Once we have the trained model, we can visualize the results to see how it performs.
ner.show_results()| TEXT | Filename | Address | Crime | Crime_datetime | Reported_date | Reported_time | Reporting_officer | Weapon | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | A convenience store clerk was robbed at gunpoi... | Example_0 | 7-Eleven, 2703 W. Beltline Highway | robbed at gunpoint Wednesday | 12/14/2017 | 9:28 AM | PIO Joel Despain | weapon | |
| 1 | A convenience store clerk was robbed at gunpoi... | Example_0 | south on Todd Dr. | robbed at gunpoint Wednesday | 12/14/2017 | 9:28 AM | PIO Joel Despain | weapon | |
| 2 | A Fordem Avenue resident reported his assault ... | Example_1 | Fordem Avenue | stolen,burglary | Friday afternoon | 04/15/2019 | 11:02 AM | PIO Joel Despain | assault rifle |
| 3 | Detectives from the MPD's Burglary Crime Unit ... | Example_2 | Watts Rd. building | stole,burglary | 02/21/2018 | 11:10 AM | PIO Joel Despain | February 10th | |
| 4 | A Milford Rd. resident returned home after wor... | Example_3 | Milford Rd. | burglarized,Jewelry and cash were taken during... | 01/18/2019 | 9:54 AM | PIO Joel Despain | ||
| 5 | Responding officers recovered a shell casing f... | Example_5 | Citgo gas station, 1423 Northport Dr. | gunfire,shot was fired as combatants drove fro... | Sunday night | 9:43 AM | PIO Joel Despain | ||
| 6 | Suspect entered Azara Hookah at 429 State Stre... | Example_6 | Azara Hookah at 429 State Street | concealing various merchandise. An employee at... | 2:18 AM | Sgt. Eugene Woehrle | knife | ||
| 7 | Suspect entered Azara Hookah at 429 State Stre... | Example_6 | University Ave. | concealing various merchandise. An employee at... | 2:18 AM | Sgt. Eugene Woehrle | knife | ||
| 8 | Detectives from the MPD's Burglary Crime Unit ... | Example_7 | Watts Rd. building | stole,burglary | 02/21/2018 | 11:10 AM | PIO Joel Despain | February 10th |
Once you are satisfied with the model, you can save it using the save() method. This creates an Esri Model Definition (EMD file) that can be used for inferencing on unseen data.
Saved models can also be loaded back using the from_model() method. The from_model() method takes the path to the emd file as a required argument.
ner.save('crime')Model has been saved to D:\task\16_guide_add_csv_support_ner\dev\data\EntityRecognizer\models\crime
WindowsPath('D:/task/16_guide_add_csv_support_ner/dev/data/EntityRecognizer/models/crime')model_path = os.path.join('data', 'EntityRecognizer', 'models', 'crime', 'crime.emd')ner = EntityRecognizer.from_model(model_path)Model inference
The trained model can be used to extract entities from new text documents using the extract_entities() function. This method accepts the path of the folder where new text documents are located, or a list of text documents from which the entities are to be extracted.
reports_path = os.path.join("data", "EntityRecognizer", "reports")results = ner.extract_entities(reports_path)results.head()| TEXT | Filename | Address | Crime | Crime_datetime | Reported_date | Reported_time | Reporting_officer | Weapon | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Officers were dispatched to a robbery of the A... | 0.txt | Associated Bank in the 1500 block of W Broadway | robbery,demanded money from a teller. No weapo... | 6:17 PM | Sgt. Jennifer Kane | |||
| 1 | The MPD was called to Pink at West Towne Mall ... | 1.txt | Pink at West Towne Mall | 08/18/2016 | 10:37 AM | PIO Joel Despain | |||
| 2 | The MPD is seeking help locating a unique $1,5... | 10.txt | Union St. | stolen,thief cut a bike lock. The Extreme Fat ... | 08/17/2016 | 11:09 AM | PIO Joel Despain | ||
| 3 | A Radcliffe Drive resident said three men - at... | 100.txt | Radcliffe Drive | armed robbery | early this | 11:17 AM | PIO Joel Despain | handguns | |
| 4 | A 10-year-old girl reported a stranger speakin... | 101.txt | Elizabeth St. | yesterday afternoon | 10:21 AM | PIO Joel Despain |
Visualize entities
We can utilize SpaCy's named entity visualizer to check the model's prediction on new text one at a time.
def color_gen(): #this function generates and returns a random color.
random_number = random.randint(0,16777215) #16777215 ~= 256x256x256(R,G,B)
hex_number = format(random_number, 'x')
hex_number = '#' + hex_number
return hex_numbercolors = {ent.upper():color_gen() for ent in ner.entities}
options = {"ents":[ent.upper() for ent in ner.entities], "colors":colors}txt = 'Multiple officers were called to an apartment building on N. Wickham Court Saturday night following reports of a large disturbance taking place inside. Officers learned there were ongoing tensions between residents of two apartments, and that some of this was the result of a gunshot the night prior. The weapons offense had not been reported to police, but officers now learned a round was fired in a common stairwell and the bullet entered an apartment, going through a bathroom before entering a bedroom wall. No one was hurt and investigators are attempting to sort out whether someone intentionally fired a gun, or if damage was the result of an accident or careless handling of a firearm. Released 12/26/2017 at 10:50 AM by PIO Joel Despain 'model_folder = os.path.join('data', 'EntityRecognizer', 'models', 'crime')nlp = spacy.load(model_folder) #path to the model folderdoc = nlp(txt)spacy.displacy.render(doc,jupyter=True, style='ent', options=options)References
[1]: Embed, encode, attend, predict: The new deep learning formula for state-of-the-art NLP models
[2]: Feature hashing
[3][Summary of the models](https://huggingface.co/transformers/summary.html)
[4][BERT Paper](https://arxiv.org/pdf/1810.04805.pdf)
[5]: Docanno
[6]: TagEditor