Introduction
RetinaNet is one of the best one-stage object detection models that has proven to work well with dense and small scale objects. For this reason, it has become a popular object detection model to be used with aerial and satellite imagery.

Figure 1. Swimming Pools detection using RetinaNet
RetinaNet has been formed by making two improvements over existing single stage object detection models - Feature Pyramid Networks (FPN) [1] and Focal Loss [2]. Before diving into RetinaNet’s architecture, let's first understand FPN.
To follow the guide below, we assume that you have some basic understanding of the convolutional neural networks (CNN) concept. You can refresh your CNN knowledge by going through this short paper “A guide to convolution arithmetic for deep learning”. It is also assumed that you have an understanding of object detection models. Please refer to the guide "How SSD Works" where concepts such as anchor boxes and feature maps have been well explained.
What's a Feature Pyramid Network?
Traditionally, in computer vision, featurized image pyramids have been used to detect objects with varying scales in an image. Featurized image pyramids are feature pyramids built upon image pyramids. This means one would take an image and subsample it into lower resolution and smaller size images (thus, forming a pyramid). Hand-engineered features are then extracted from each layer in the pyramid to detect the objects [1]. This makes the pyramid scale-invariant. But, this process is compute and memory intensive.
With the advent of deep learning, these hand-engineered features were replaced by CNNs. Later, the pyramid itself was derived from the inherent pyramidal hierarchical structure of the CNNs. In a CNN architecture, the output size of feature maps decreases after each successive block of convolutional operations, and forms a pyramidal structure.
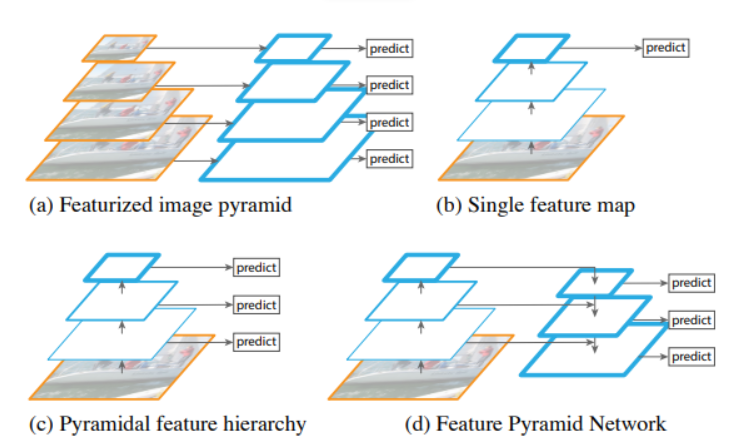
Figure 2. Different types of pyramid architectures [1]
There have been various architectures that utilize the pyramid structure (Figure 2). The (a) Featurized image pyramid, as we have discussed, is compute intensive. (b) Single (scale) feature maps have been used for faster detections. Even though they are robust and fast, pyramids are still needed to get the most accurate results [1]. (c) Pyramidal feature hierarchy has been utilized by models such as Single Shot detector, but it doesn't reuse the multi-scale feature maps from different layers. (d) Feature Pyramid Network (FPN) makes up for the shortcomings in these variations. FPN creates an architecture with rich semantics at all levels as it combines low-resolution semantically strong features with high-resolution semantically weak features [1]. This is achieved by creating a top-down pathway with lateral connections to bottom-up convolutional layers.
Top-down pathway, bottom-up pathway and lateral connections will be better understood in the next section when we take a look at the RetinaNet architecture. RetinaNet incorporates FPN and adds classification and regression subnetworks to create an object detection model.
RetinaNet architecture
There are four major components of a RetinaNet model architecture (Figure 3):
a) Bottom-up Pathway - The backbone network (e.g. ResNet) which calculates the feature maps at different scales, irrespective of the input image size or the backbone.
b) Top-down pathway and Lateral connections - The top down pathway upsamples the spatially coarser feature maps from higher pyramid levels, and the lateral connections merge the top-down layers and the bottom-up layers with the same spatial size.
c) Classification subnetwork - It predicts the probability of an object being present at each spatial location for each anchor box and object class.
d) Regression subnetwork - It's regresses the offset for the bounding boxes from the anchor boxes for each ground-truth object.
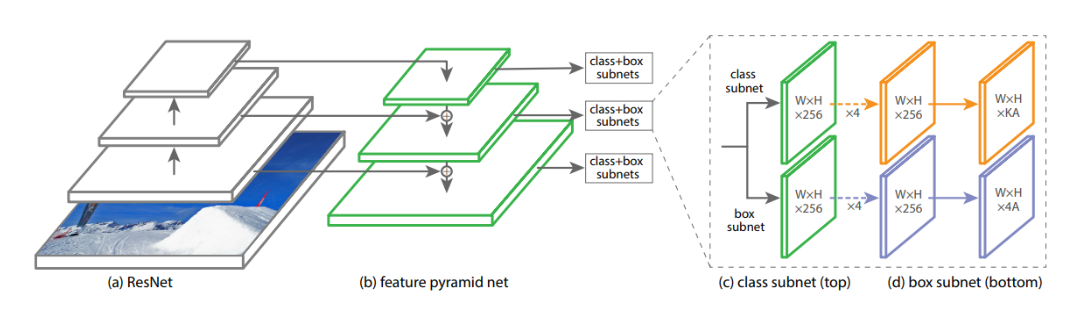
Figure 3. RetinaNet model architecture [2]
Focal Loss
Focal Loss (FL) is an enhancement over Cross-Entropy Loss (CE) and is introduced to handle the class imbalance problem with single-stage object detection models. Single Stage models suffer from a extreme foreground-background class imbalance problem due to dense sampling of anchor boxes (possible object locations) [2]. In RetinaNet, at each pyramid layer there can be thousands of anchor boxes. Only a few will be assigned to a ground-truth object while the vast majority will be background class. These easy examples (detections with high probabilities) although resulting in small loss values can collectively overwhelm the model. Focal Loss reduces the loss contribution from easy examples and increases the importance of correcting missclassified examples.
Implementation in arcgis.learn
You can create a RetinaNet model in arcgis.learn using a single line of code.
model = RetinaNet(data)
The important parameters to be passed are:
- The
datathat you would have prepared in the earlier steps. - A
backbonemodel from the ResNet family. The default is set to ResNet50. scalesof anchor boxes. The default is set to [2^0, 2^⅓, 2^⅔ ] which works well with most of the objects in any datasets. You can change the scales according to the size of objects in your dataset.- aspect
ratiosof anchor boxes. The default is set to [0.5, 1, 2] which means the anchor boxes will be of aspect ratios 1:2, 1:1, 2:1. You can modify the ratios according to the shape of the objects of interest.
Tuning these parameters is based on intuition built through understanding the model and experimenting on the dataset.
For more information about the API, please go to the API reference.
References
- [1] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan: “Feature Pyramid Networks for Object Detection”, 2016; [http://arxiv.org/abs/1612.03144 arXiv:1612.03144].
- [2] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He: “Focal Loss for Dense Object Detection”, 2017; [http://arxiv.org/abs/1708.02002 arXiv:1708.02002].