Introduction
We have seen how the one-shot object detection models such as SSD, RetinaNet, and YOLOv3 work. However, before the single-stage detectors were the norm, the most popular object detectors were from the multi-stage R-CNN family. First, there was R-CNN, then Fast R-CNN came along with some improvements, and then eventually, Faster R-CNN became the state-of-the-art multi-stage object detector. As is obvious from the names, these models evolved from one to the next, providing better performance at faster speeds. Although Faster R-CNN is not as fast as some of the later single-stage models, it remains one of the most accurate object detection models.

Figure 1. Object Detection using Faster R-CNN [1]
Earlier works
R-CNN
R-CNN (Regions with Convolutional Neural Networks) architecture is a combination of multiple algorithms put together. It first uses a selection search algorithm to select 2000 region proposals that might contain objects. Each of these region proposals or Regions of Interest (RoIs) is processed through a convolutional net to obtain feature maps. The feature maps are then passed to an SVM model to classify the object class and to a regression model to obtain tight bounding boxes [2]. This method, although novel at the time, is extremely slow. You can read more about R-CNN here.
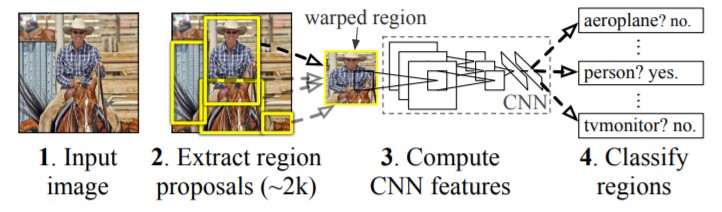
Figure 2. R-CNN Architecture [2]
Fast R-CNN
Fast R-CNN came in as an improvement over R-CNN. In this model, instead of feeding each of the 2000 regions to separate CNNs, the whole image is fed to a single CNN. This results in a combined feature map for all the regions of interest. Region proposals are selected using an algorithm similar to the one used in R-CNN. An RoI pooling layer is used to extract and resize the feature maps of all the region proposals to the same size. This is then passed on to fully connected layers having two branches - a softmax classifier to give probabilities for each class and a bounding box regressor for precise bounding box coordinates [3]. This design speeds up the object detection task in comparison to R-CNN but still isn't good enough to work with large datasets. You can read more about Fast R-CNN here.
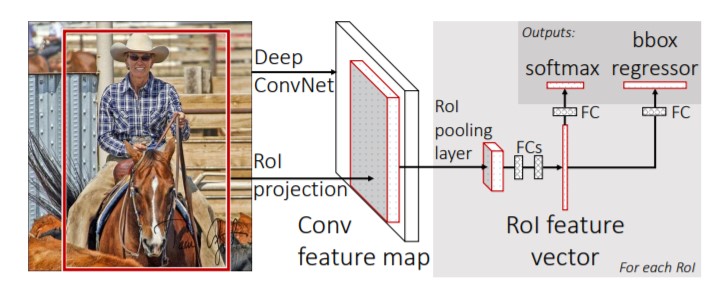
Figure 3. Fast R-CNN Architecture [3]
Faster R-CNN
Until Faster R-CNN came out, its contemporaries were using various algorithms for region proposal that were being computed on the CPU and creating a bottleneck. Faster R-CNN improved the object detection architecture by replacing the selection search algorithm in Fast R-CNN with a convolutional network called the Region Proposal Network (RPN). The rest of the model architecture remains the same as Fast R-CNN - the image is fed to a CNN to produce a feature map from which features for regions proposed by the RPN are selected and resized by a pooling layer and fed to an FC layer with two heads, a softmax classifier, and a bounding box regressor. This design increased the speed of detection and brought it closer to realtime [1].
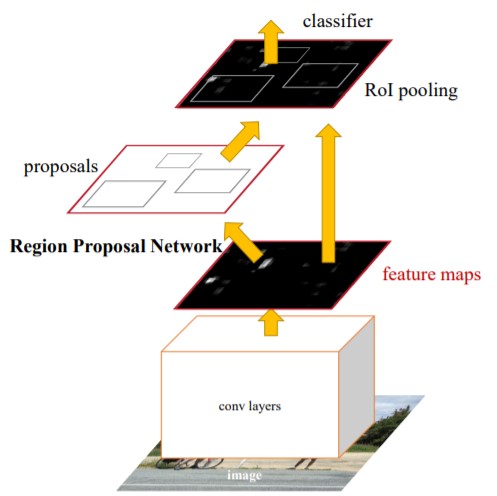
Figure 4. Faster R-CNN Architecture [1]
Region Proposal Network (RPN)
Region Proposal Network like other region proposal algorithms inputs an image and returns regions of interest that contain objects. An RPN also returns an objectness score that measures how likely the region is to have an object vs. a background [1]. In Faster R-CNN, the RPN and the detect network share the same backbone. The last shared layer of the backbone provides a feature map of the image that is used by the RPN to propose regions.
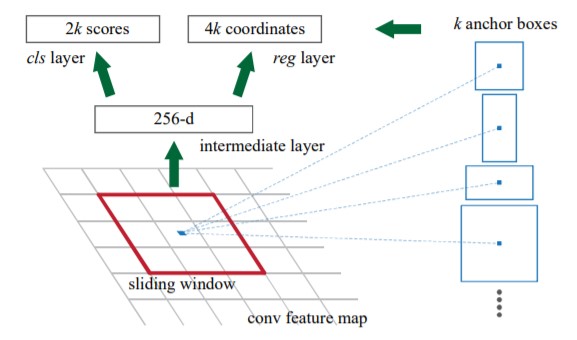
Figure 5. Region Proposal Network [1]
Using a sliding window approach, a small network is overlaid onto the feature map. At each spatial window, there are multiple anchor boxes that are of predetermined scales and aspect ratios. This enables the model to detect objects of a wide range of scales and aspect ratios in the same image. Usually, three different scales and three different aspect ratios are used resulting in nine anchor boxes at each spatial location that denotes the maximum region proposals at that spatial location. The small network then feeds into fully connected layers with two heads - one for the objectness score and the other for the bounding box coordinates of the region proposals. Figure 5, demonstrates the sliding window at a spatial location, the corresponding anchor boxes and how it feeds into the subsequent layers [1]. Note that these layers though similar to the last few layers of the Fast R-CNN object detector are not the same nor do they share the weights. The RPN classifies the regions in a class agnostic manner as it is tasked with only finding the regions which contain the objects.
In this guide, we have tried to present an intuition to understand the Faster R-CNN model. To dive into more details about the model and it's architecture, please read the original papers mentioned in references below. You can reference this blog.
Implementation in arcgis.learn
You can create a Faster R-CNN model in arcgis.learn using a single line of code.
model = FasterRCNN(data)
Where data is the databunch that you would have prepared using prepare_data function.
Optionally, a backbone model from the ResNet family can be provided. The default is set to resnet50.
For more information about the API, please go to the API reference.
References
[1] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun: “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”, 2015; [http://arxiv.org/abs/1506.01497 arXiv:1506.01497].
[2] Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik: “Rich feature hierarchies for accurate object detection and semantic segmentation”, 2013; [http://arxiv.org/abs/1311.2524 arXiv:1311.2524].
[3] Ross Girshick: “Fast R-CNN”, 2015; [http://arxiv.org/abs/1504.08083 arXiv:1504.08083].