SuperResolution is an image transformation technique with the help of which we can improve the quality of image and recover high resolution image from a given low resolution image as shown in Figure 1. It allows us to remove the compression artifacts and transform the blurred images to sharper images by modifying the pixels.

Figure 1. Recovering high resolution image from low resolution
This model uses deep learning to add texture and detail to low resolution satellite imagery and turn it into higher resolution imagery. The model training requires pairs of high and low resolution imagery of the same area. In order to train the model, we only require high resolution imagery, and prepare_data in arcgis.learn will degrade the high resolution imagery in order to simulate low resolution image for training the model.
Model Architecture
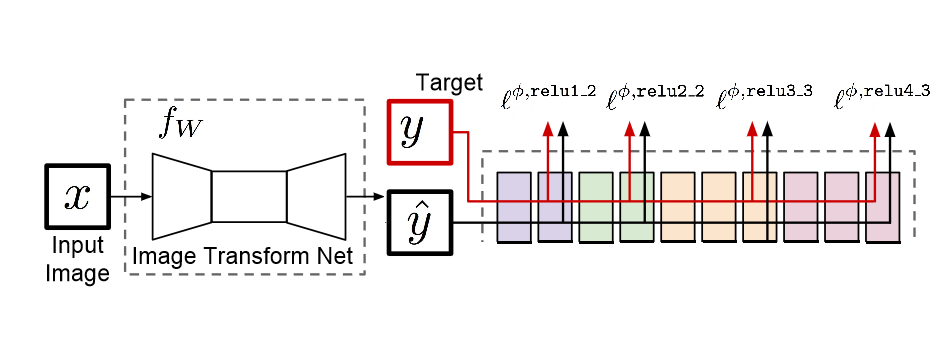
Figure 2. Overview of SuperResolution architecture [1]
We are using Unet as our image transformation network and VGG-16 as our network for feature loss.
-
Image transformation network (Unet): This network is parameterized by weights and takes the input images, transforms them by modifying pixels and generate the output image. To learn about Unet, you can refer to our guide How Unet works?.
-
Loss Network (VGG-16): This network is pretrained on ImageNet data in which weights remain fixed during the training process. We use feature layers of this network to generate loss, which is known as perceptual loss.
Perceptual Loss
The model with per pixel loss alone try to match exactly each pixel of the generated and the target image. The two images look similar in perspective, but they might have different per-pixels values hence it gives a blurry kind of image. To improve on that, we use Perceptual Loss. It combines per pixel loss and the feature loss from the different layers of Loss Network, which captures both per pixel difference and high-level image feature representations extracted from pretrained CNN.
In the whole process, the low resolution image is fed into the image transformation network, which does the prediction $\hat{y}$ as a high resolution image. The predicted images $\hat{y}$ and the ground truth images $y$ are then fed into the loss network, where the perceptual loss between the two images is calculated.
SuperResolution implementation in arcgis.learn
First, we have to create a databunch with prepare_data function in arcgis.learn
data = arcgis.learn.prepare_data(path=r"path/to/exported/data", downsample_factor=4)
The important parameters to be passed are:
- The
pathto the Data directory. The directory should contain high resolution or both high and low resolution paired images. - The
downsample factorto generate labels for training. It takes high resolution images and uses methods such as bilinear interpolation to reduce the size and degrade the quality of the image. For example: Image of dimensions 256x256 is converted to 64x64 with downsample factor of 4.
We can then continue with basic arcgis.learn workflow. To learn more about the workflow of SuperResolution model, you can refer to the sample notebook.
For more information about the API & model, please go to the API reference.
References
[1] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for realtime style transfer and super-resolution”, 2016; arXiv:1603.08155.