Many of the poorest neighborhoods in the City of Chicago face violent crimes. Since some studies have linked alcohol to different crimes, there is pressure on the city officials to close down liquor establishments. The local business owners, on the other hand, want to block such restrictions as it could negatively impact business and the social fabric of the City. In this sample, we will perform an illustrative analysis to find a find a possible relation between violent crimes and liquor establishments. This will also help us figure out if poverty and unemployment rate are factors which contribute to more crimes in a specific area of the city. We will be using the Crime Analysis data from ArcGIS Living Atlas of the World in order to perform this analysis. The data was orginally obtained from the 2014 Violent Crime Data in the City of Chicago data portal (https://data.cityofchicago.org).
Through this sample, we will demonstrate the utility of a number of spatial analysis methods including hot spot analysis, feature overlay, data enrichment and spatial selection using ArGIS API for Python.
Further, based on the results of the analysis, this sample will try to assist with an effective solution to this problem.

Outline of Steps
We will use the following workflow for the analysis:
- Retrieve Crime Analysis data.
- Plot the data on map for visualzation
- Perform spatial analysis:
- We will first create hotspots for the crime densities and liquor vendor layers. This will help is in visualizing the significant areas of crime incidences and liquor vendors.
- Enrich the crime layer with poverty and unemployment rate data using the enrich_layer tool.
- Visualize hotspots on the enriched layers.
- Use overlay tool to find relationship between crimes and liquor establishments. This will also help to know whether or not poverty and unemployment rate are factors contributing to more crimes in any specific area of the city.
- Suggest ways for reducing crime based on the results of our analysis
Necessary Imports
from datetime import datetime as dt
from IPython.display import display
from arcgis import GIS
from arcgis.features.analyze_patterns import find_hot_spots
from arcgis.features.enrich_data import enrich_layer
from arcgis.features.manage_data import overlay_layers
from arcgis.features.find_locations import find_existing_locations Connect to your GIS
gis = GIS('home')Get the data for the analysis
Search for CrimeAnalysisData layer in ArcGIS Online. We can search for content shared by users outside our organization by setting outside_org to True.
items = gis.content.search('title:CrimeAnalysisData owner:api_data_owner', 'feature layer')for item in items:
display(item)
We will use the first item for our analysis. Since the item is a Feature Layer Collection, accessing the layers property will give us a list of FeatureLayer objects.
crime_item = items[0]lyrs = crime_item.layersThe code below cycles through the layers and prints their names.
for lyr in lyrs:
print(lyr.properties.name)Public High Schools Liquor Vendors Violent Crime 2014 Analysis Boundary
We'll get the second layer and assign it to the violent_crimes variable. Similarly, get the analysis_boundary layer.
violent_crimes = lyrs[2] # Violent Crime 2014analysis_boundary = lyrs[3] # Analysis BoundaryLet's visualize the crime incidents on a map of Chicago.
crime_map = gis.map('Chicago')
crime_map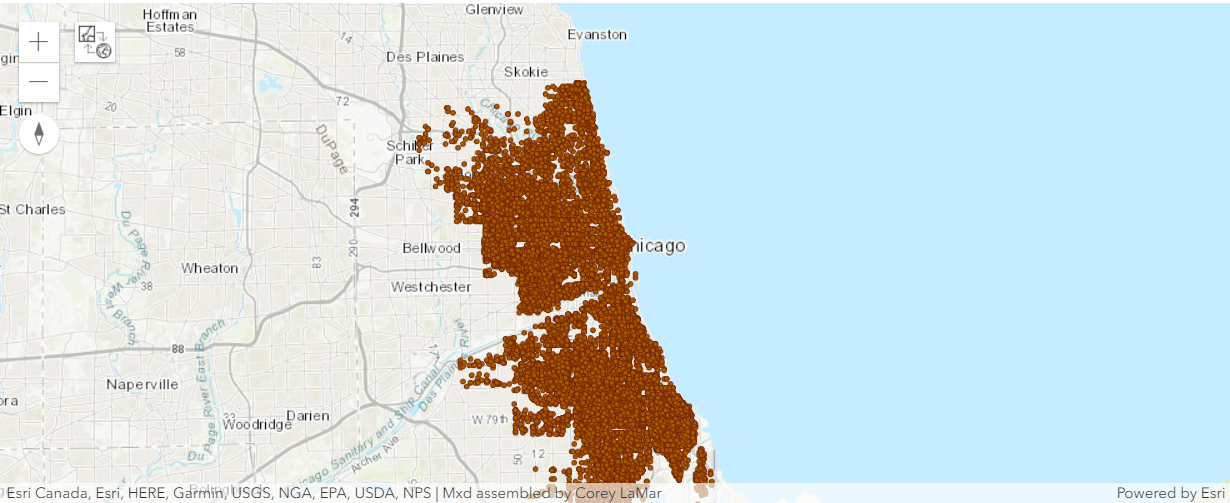
crime_map.content.add(violent_crimes)It is difficult to discern spatial patterns with so many points on the map. To make sense of the more than 22,000 crime points, and over 1,500 business points, we will map them using hot spot analysis.
We can add a number of different layer objects such as FeatureLayer, FeatureCollection, ImageryLayer, MapImageLayer to the map by calling the add_layer() method.
Create a hot spot map of violent crime densities
ArcGIS has a set of tools to help us identify, quantify and visualize satial patterns in our data by identifying areas of statistically significant clusters.
The find_hot_spots tool allows us to visualize areas having such clusters.
crime_hot_spots = find_hot_spots(violent_crimes,
output_name='ViolentCrimeHotSpots' + str(dt.now().microsecond),
bounding_polygon_layer=analysis_boundary)crime_hot_spots
crime_spots_map = gis.map('Chicago')
crime_spots_map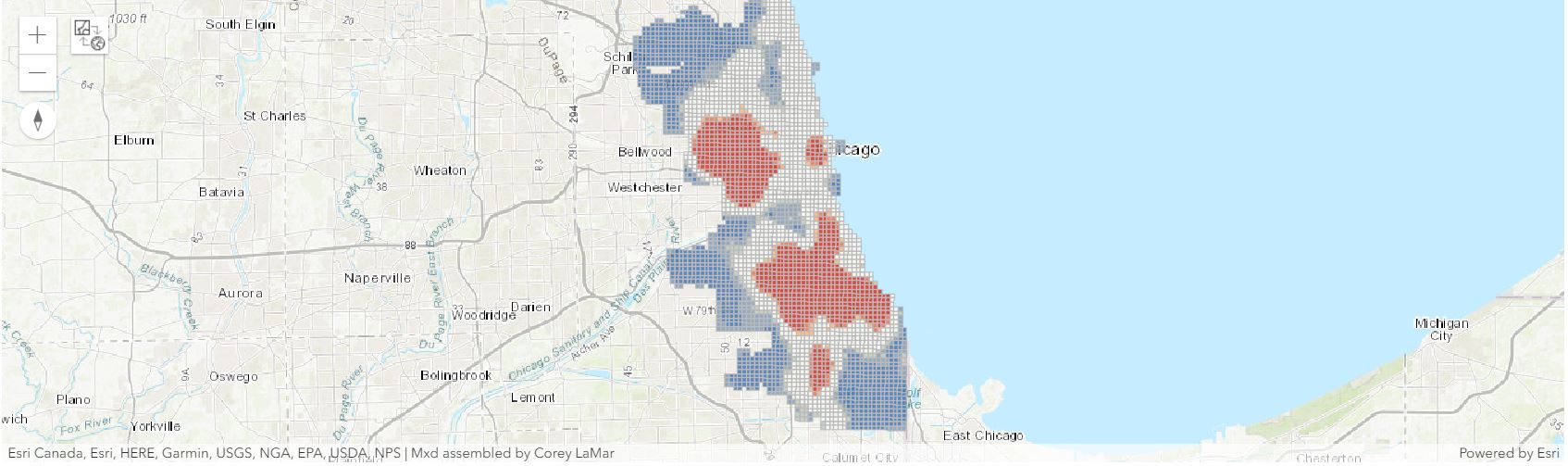
This map shows us the statistically significant hot spots (red) and cold spots (blue) for violent crime.
crime_spots_map.content.add(crime_hot_spots)Next, we will use the liquor_vendors layer.
liquor_vendors = lyrs[1]Create a hot spot map of liquor vendors to compare to the violent crime hot spot map
liquor_vendor_hot_spots = find_hot_spots(liquor_vendors,
output_name='LiquorVendorHotSpots' + str(dt.now().microsecond),
aggregation_polygon_layer=crime_hot_spots)liquor_vendor_hot_spotsliquor_vendor_hot_spots_lyr = liquor_vendor_hot_spots.layers[0]liquor_hot_spots_map = gis.map('Chicago')
liquor_hot_spots_map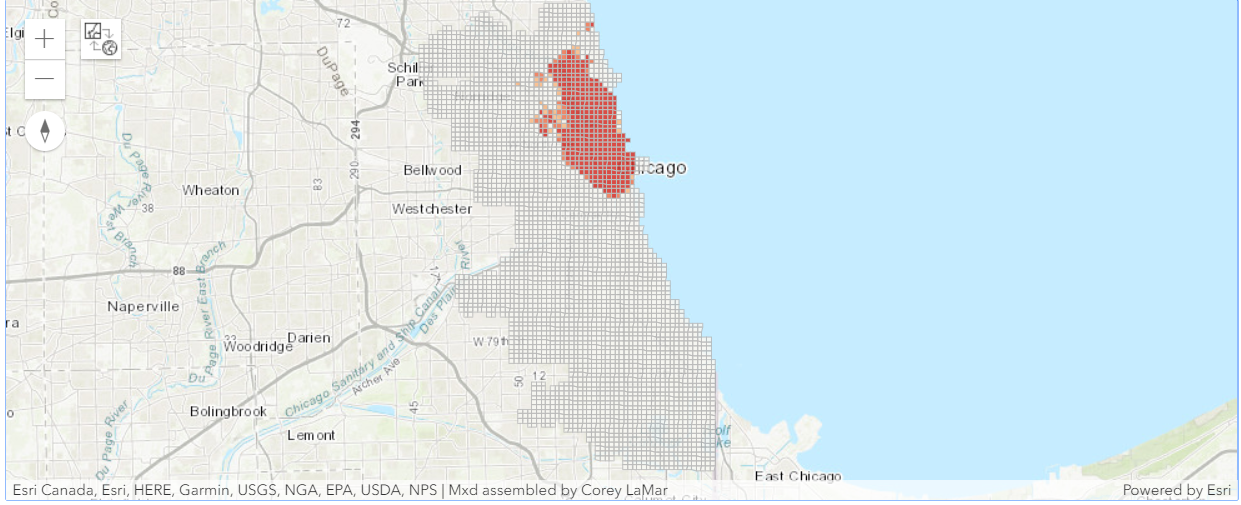
This map shows us the statistically significant hot spots (red) and cold spots (blue) for liquor establishments..
liquor_hot_spots_map.content.add(liquor_vendor_hot_spots_lyr)In order to identify the city's most vulnerable neighborhoods, we will obtain the data needed to create a hot spot map of poverty.
Get poverty data for each of the polygon grids in the violent crime hot spot analysis layer
The enrich_layer tool gives us demographic and landascape data for the people, places, and businesses in a specific area, or within a selected travel time or distance from a location.
We will add analysis variables, i.e, poverty, to our layer. This will enrich our layer with the poverty data.
Note: Organizations should review the data attributions and Master Agreement to make sure they are in compliance when geoenriching data and making it available to other systems.
poverty_enrich= enrich_layer(crime_hot_spots,
analysis_variables=["households.ACSHHBPOV"],
output_name='PovertyDataEnrichedLayer' + str(dt.now().microsecond))poverty_enrichpoverty_enrich_lyr = poverty_enrich.layers[0]Create a hot spot map of poverty
We can find hot spots of the enriched_layer by assigning the field name of the analysis variable to parameter 'analysis_field'.
poverty_data_hot_spots = find_hot_spots(poverty_enrich_lyr,
analysis_field='ACSHHBPOV',
output_name='povertyEnrichedHotSpots' + str(dt.now().microsecond))Load the map again to visualize the poverty_data_hot_spots
poverty_data_hot_spots_map = gis.map('Chicago')
poverty_data_hot_spots_map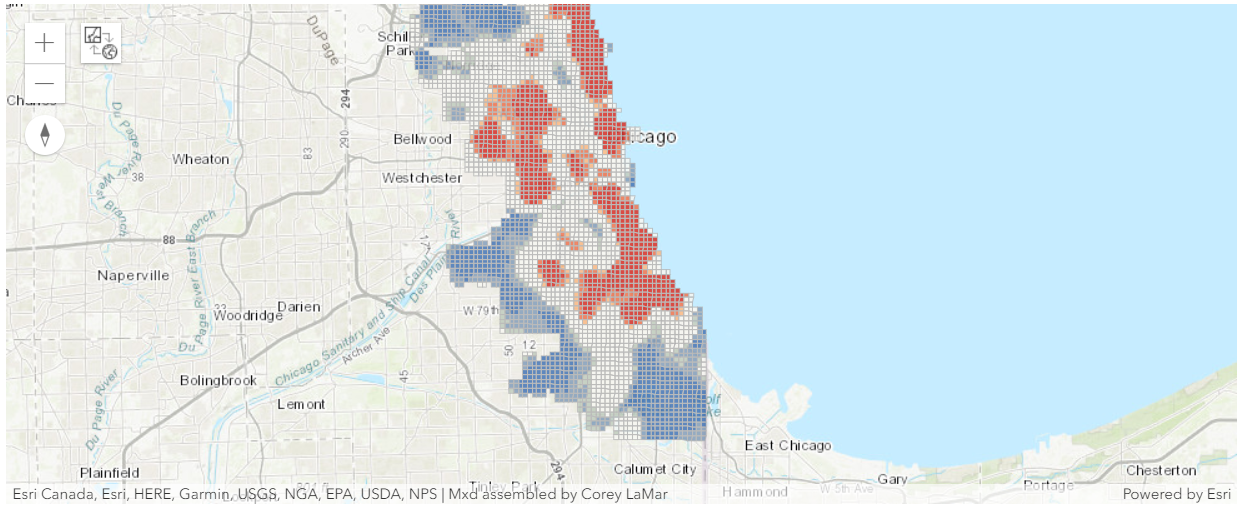
poverty_data_hot_spots_map.content.add(poverty_data_hot_spots)The red areas are statistically significant hot spots for poverty.
We will now filter the three variables, i.e., violent crime, existing liquor establishments, and poverty in order to get statistically significant hot spots.
Overlay the violent crime and liquor vendor to find where they overlap.
We will assign the Gi_Bin attribute a value of 3 in order to get statistically significant hot spots at 99 percent confidence level.
crimelayer = crime_hot_spots.layers[0]
crimelayer.filter = "Gi_Bin = 3"liquorlayer = liquor_vendor_hot_spots.layers[0]
liquorlayer.filter = "Gi_Bin = 3"povertylayer = poverty_data_hot_spots.layers[0]
povertylayer.filter = "Gi_Bin = 3"The overlay_layers function combines two or more layers into one single layer using an intersect, union, or erase method. We can think of overlay as peering through a stack of maps and creating a single map containing all the information found in the stack.
We will use the crimelayer as the input layer and intersect it with the liquorlayer.
intersect_of_crime_vendor = overlay_layers(crimelayer,
liquorlayer,
tolerance=0,
context={},
output_name="IntersectOfCrimeVendor" + str(dt.now().microsecond))intersect_of_crime_vendorOverlay the violent crime, liquor vendor and poverty hot spot maps to find where they overlap
intersect_cri_pov_liq = overlay_layers(intersect_of_crime_vendor,
poverty_data_hot_spots,
output_name="intersectOfCrimeVendorPoverty" + str(dt.now().microsecond))intersect_cri_pov_liqNext, we will load the overlay layer on the map.
intersected_map = gis.map('Chicago')
intersected_map
intersected_map.content.add(intersect_cri_pov_liq)With the exception of the small overlapping areas identified above, we find no spatial correlation between violent crime and businesses that sell or serve alcohol.
However since violent crimes are serious problem in the city, we will look into the current research in this area in order to provide a possible solution to this problem.
A recent research indicates that two years ago the City implemented a summer jobs program that proved tremendously effective in reducing violent crime. So we will obtain unemployment data and repeat our hot spot analysis to see if we find a stronger spatial correlation between unemployment and violent crime than we did between liquor establishments and violent crime.
Get the unemployment rate data matching the violent crime trends layer
The space-time pattern mining tools are not currently available in ArcGIS API for Python which are required to create crime trend map. Although we can create the crime trend map using ArcMap or using ArcGIS Pro . For our analysis we will use the layer already published in ArcGIS Online. To access the layer, search for ViolentCrimeTrend in ArcGIS Online. We can search the GIS for feature layer collections by specifying the item type as 'Feature Layer Collection' or 'Feature Layer'.
crime_trend = gis.content.search('title:ViolentCrimeTrend owner: api_data_owner', 'feature layer')
crime_trend_item = crime_trend[0]
crime_trend_layer = crime_trend_item.layers[0]We will use the enrich_layer tool to add more demographic information to the layer.
crime_trend_unemp_enrich = enrich_layer(crime_trend_layer,
analysis_variables=["industry.UNEMPRT_CY"],
output_name='UnemploymentEnrichedLayer' + str(dt.now().microsecond))Create a hot spot map of the unemployment rate data
We use find_hot_spots tool to spot hot spots of crime_trend_enriched_unemployment layer.
unemployment_rate_hot_spots = find_hot_spots(crime_trend_unemp_enrich,
analysis_field='UNEMPRT_CY',
output_name='UnemploymentRateHotspots' + str(dt.now().microsecond))Now let's load and visualize the hot spots on the map.
unemployment_rate_hot_spots_map = gis.map('Chicago')
unemployment_rate_hot_spots_map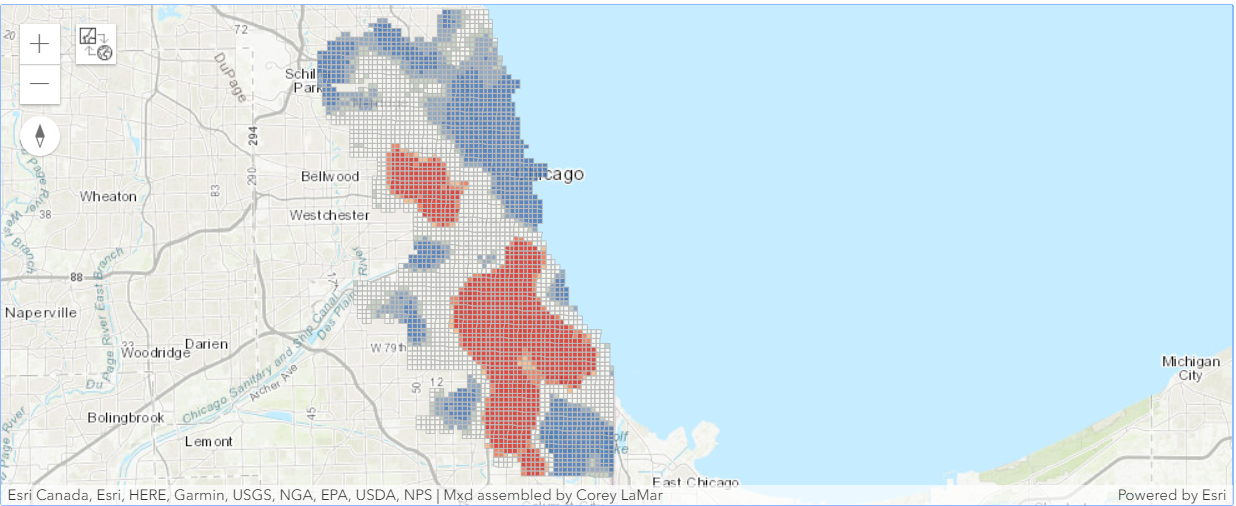
unemployment_rate_hot_spots_map.content.add(unemployment_rate_hot_spots)Overlay the crime trends map with the unemployment hot spot map
We will filter unemployment_rate_hot_spots to select locations where the Gi_Bin Fixed 4554_FDR field is 3 (3 is the code for statistically significant hot spots at the 99 percent confidence level, as we mentioned earlier). Then we will filter the most intense unemployment hot spots
unemployment_rate_hot_spots.layers[0].filter = "Gi_Bin = 3"For the crime trends map, we are interested in specific Pattern Type values: Intensifying, Consecutive, and Persistent hot spots.
crime_trend_layer.filter = "(PATTERN = 'Consecutive Hot Spot') OR (PATTERN ='Intensifying Hot Spot') OR (PATTERN = 'Persistent Hot Spot')"We use overlay_layers tool to find areas that are common to crime trend layer and unemployment_rate_hot_spots.
overlay_unemp_crime = overlay_layers(crime_trend_layer,
unemployment_rate_hot_spots,
output_name="OverlayUnEmploymentCrimetrend" + str(dt.now().microsecond))overlay_unemp_crimeNow let's load and visualize on map.
overlay_map = gis.map('Chicago')
overlay_map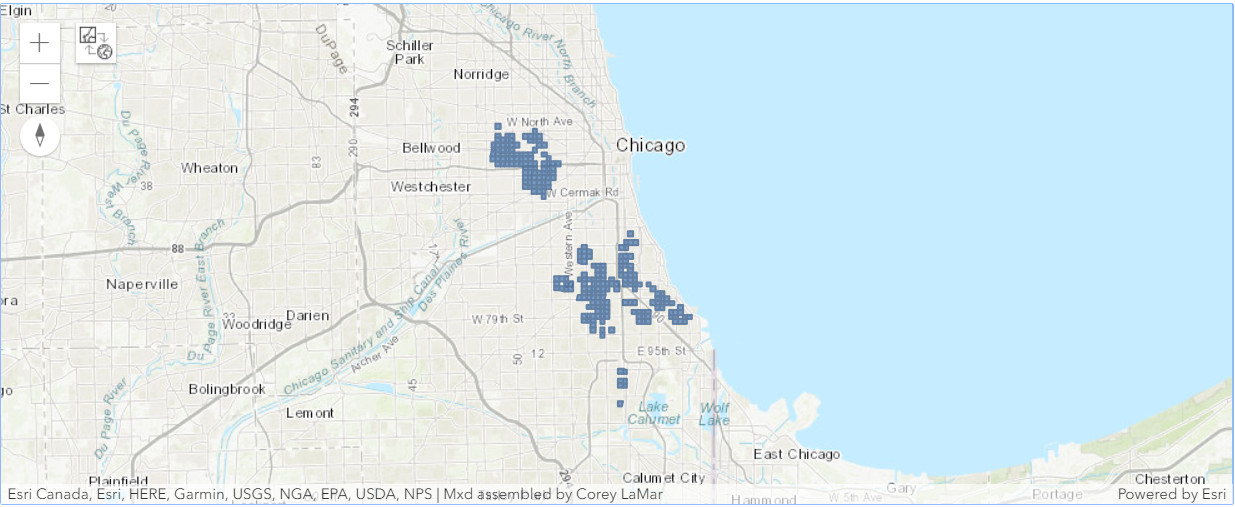
overlay_map.content.add(overlay_unemp_crime)We indeed find that there are a number of locations where the violent crime and unemployment hot spots overlap.
The blue areas are the locations where intensifying, persistent, and consecutive hot spot trends overlap with the most intense unemployment hot spots.
High schools within a quarter mile of the remediation areas where high violent crime and high unemployment overlap should be targeted for an expanded summer jobs program.So we will identify such schools.
Select the high schools falling within a quarter mile of the proposed remediation areas
public_high_school_layer = lyrs[0]selected_schools = find_existing_locations(input_layers=[{'url': public_high_school_layer.url},
{'url': crime_trend_unemp_enrich.layers[0].url}],
expressions=[{"operator":"",
"layer":0,
"selectingLayer":1,
"spatialRel":"withinDistance",
"distance":0.25,
"units":"Miles"}],
output_name='SelectedSchools' + str(dt.now().microsecond))selected_schoolsselected_high_schools_map = gis.map('Chicago')
selected_high_schools_map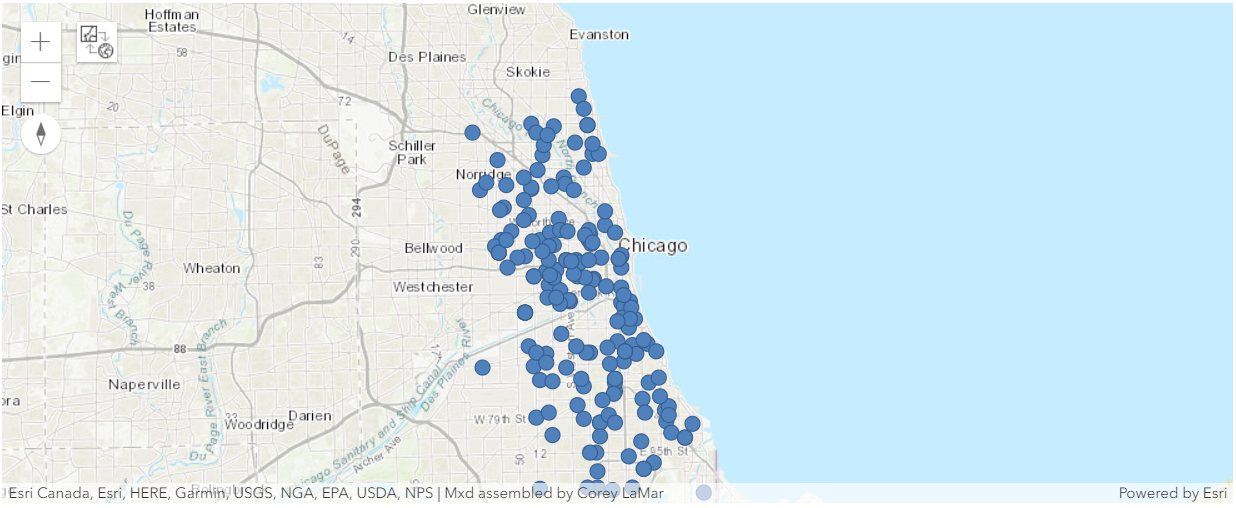
selected_high_schools_map.content.add(selected_schools)Conclusion
In this study, we performed hotspot analysis on violent crimes layer and liquor vendors layer. We enriched the crime hotspots layer with poverty indicators and produced a poverty hotspot layer. When all 3 layers were overlaid, we found no spatial correlation. In the next step, we enriched the crime layer with unemployment information and produced an unemployment hotspot layer. However, this layer was spatially correlated with the crimes layer when overlaid. As a solution, we used find_existing_locations tools to identify high schools within 0.25 miles of places with high crime and high unemployment as candidates for summer programs as an abatement measure.
Summary of tools
| Method | Examples |
|---|---|
| Hot Spot Analysis of feature attributes | Where are the statistically significant clusters of poverty, unemployment, wealth, beer drinkers, lead levels, or college graduates? |
| Feature Overlay | Where are the intersections among high crime areas, high liquor vendor areas, and high poverty areas? Where are high lead levels and poor educational outcomes spatially congruent? |
| Spatial Selection | Which schools are close to the remediation areas? Which homes fall within the flood zone? Which ZIP Codes are within the county? |
| Data Enrich | Which aeas have high poverty and unemployment rate? |
Terms of use
In keeping with the requirements of the City of Chicago Data Portal terms of data use, note the following: This case study describes analyses using data that have been modified for use from its original source, www.cityofchicago.org, the official website of the City of Chicago. The City of Chicago makes no claims as to the content, accuracy, timeliness, or completeness of any of the data provided at this site. The data provided at this site is subject to change at any time. It is understood that the data provided at this site is being used at one's own risk.