- Introduction
- Importing libraries
- Connecting to your GIS
- Accessing & visualizing the dataset
- Time series data preprocessing
- Time series model building
- Air temperature forecast & validation
- Conclusion
- Summary of methods used
- References
- Data resources
Introduction
A rise in air temperature is directly correlated with Global warming and change in climatic conditions and is one of the main factors in predicting other meteorological variables, like streamflow, evapotranspiration, and solar radiation. As such, accurate forecasting of this variable is vital in pursuing the mitigation of environmental and economic destruction. Including the dependency of air temperature in other variables, like wind speed or precipitation, helps in deriving more precise predictions. In this study, the deep learning TimeSeriesModel from arcgis.learn is used to predict monthly air temperature for two years at a ground station at the Fresno Yosemite International Airport in California, USA. The dataset ranges from 1948-2015. Data from January 2014 to November 2015 is used to validate the quality of the forecast.
Univariate time series modeling is one of the more popular applications of time series analysis. This study includes multivariate time series analysis, which is a bit more convoluted, as the dataset contains more than one time-dependent variable. The TimeSeriesModel from arcgis.learn includes backbones, such as InceptionTime, ResCNN, ResNet and FCN, which do not need fine-tuning of multiple hyperparameters before fitting the model. Here is the schematic flow chart of the methodology:

Importing libraries
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pandas.plotting import autocorrelation_plot as aplot
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
import sklearn.metrics as metrics
from arcgis.gis import GIS
from arcgis.learn import TimeSeriesModel, prepare_tabulardata
from arcgis.features import FeatureLayer, FeatureLayerCollectionConnecting to your GIS
gis = GIS('home')Accessing & visualizing the dataset
The data used in this sample study is a multivariate monthly time series dataset recorded at a ground station in the Fresno Yosemite International Airport, California, USA. It ranges from January 1948 to November 2015.
# Location of the ground station
location = gis.map(location="Fresno Yosemite International California", zoomlevel=12)
location
# Access the data table
data_table = gis.content.get("8c58e808aabd40408f7bc4eeac64fffb")
data_table
# Visualize as pandas dataframe
climate_data = data_table.tables[0]
climate_df = climate_data.query().sdf
climate_df.head()| STATION | NAME | DATE | AWND | PRCP | PSUN | SNOW | TAVG | TMAX | TMIN | TSUN | WSFG | ObjectId | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | USW00093193 | FRESNO YOSEMITE INTERNATIONAL, CA US | 1948-01-01 | None | 0.00 | None | 0 | 51.2 | 66.3 | 36.2 | None | None | 1 |
| 1 | USW00093193 | FRESNO YOSEMITE INTERNATIONAL, CA US | 1948-02-01 | None | 0.78 | None | 0 | 49.0 | 62.2 | 35.8 | None | None | 2 |
| 2 | USW00093193 | FRESNO YOSEMITE INTERNATIONAL, CA US | 1948-03-01 | None | 2.29 | None | 0 | 53.2 | 65.6 | 40.7 | None | None | 3 |
| 3 | USW00093193 | FRESNO YOSEMITE INTERNATIONAL, CA US | 1948-04-01 | None | 2.28 | None | 0 | 59.8 | 71.8 | 47.7 | None | None | 4 |
| 4 | USW00093193 | FRESNO YOSEMITE INTERNATIONAL, CA US | 1948-05-01 | None | 0.96 | None | 0 | 65.2 | 79.7 | 50.7 | None | None | 5 |
The dataframe above contains columns for station ID (STATION), station name (NAME), Date (DATE), Wind speed (AWND), precipitation (PRCP), possible sunshine (PSUN), snow cover (SNOW), average temperature (TAVG), maximum temperature (TMAX), minimum temperature (TMIN), total sunshine (TSUN), and peak wind gust speed (WSFG).
climate_df.shape(815, 13)
Next, the dataset is prepared by dropping the variables for station, possible sunshine, snow cover, maximum temperature, minimum temperature, total sunshine, and peak wind gust speed. Then, the dataset is narrowed to the data from 1987 on, to avoid missing values.
climate_df = climate_df.drop(
["ObjectId", "STATION", "NAME", "PSUN", "SNOW", "TSUN",'TMAX', 'TMIN', "WSFG"], axis=1
)climate_df.columnsIndex(['DATE', 'AWND', 'PRCP', 'TAVG'], dtype='object')
# Selecting dataset from year 1987 to get continous data without NAN values
selected_df = climate_df[climate_df.DATE > "1987"]
selected_df.head()| DATE | AWND | PRCP | TAVG | |
|---|---|---|---|---|
| 469 | 1987-02-01 | 5.8 | 1.36 | 52.7 |
| 470 | 1987-03-01 | 6.3 | 2.39 | 55.6 |
| 471 | 1987-04-01 | 6.9 | 0.07 | 66.6 |
| 472 | 1987-05-01 | 7.4 | 0.87 | 71.8 |
| 473 | 1987-06-01 | 7.4 | 0.01 | 78.4 |
Here, TAVG is our variable to be predicted, with PRCP and AWND being the predictors used, showing their influence on temperature.
selected_df.shape(346, 4)
Time series data preprocessing
The preprocessing of the data for multivariate time series modeling involves the following steps:
Converting into time series format
The dataset is now transformed into a time series data format by creating a new index that will be used by the model for processing the sequential data.
final_df = selected_df.reset_index()
final_df = final_df.drop("index", axis=1)
final_df.head()| DATE | AWND | PRCP | TAVG | |
|---|---|---|---|---|
| 0 | 1987-02-01 | 5.8 | 1.36 | 52.7 |
| 1 | 1987-03-01 | 6.3 | 2.39 | 55.6 |
| 2 | 1987-04-01 | 6.9 | 0.07 | 66.6 |
| 3 | 1987-05-01 | 7.4 | 0.87 | 71.8 |
| 4 | 1987-06-01 | 7.4 | 0.01 | 78.4 |
Data types of time series variables
Here we check the data types of the variables.
final_df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 346 entries, 0 to 345 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 DATE 346 non-null datetime64[ns] 1 AWND 346 non-null object 2 PRCP 346 non-null float64 3 TAVG 346 non-null float64 dtypes: datetime64[ns](1), float64(2), object(1) memory usage: 10.9+ KB
The time-dependent variables should of the type float. If a time-dependent variable is not of a float data type, then it needs to be changed to float. Here, Windspeed (AWND) is converted from object dtype to float64, as shown in the next cell.
final_df["AWND"] = final_df["AWND"].astype("float64")
final_df.head()| DATE | AWND | PRCP | TAVG | |
|---|---|---|---|---|
| 0 | 1987-02-01 | 5.8 | 1.36 | 52.7 |
| 1 | 1987-03-01 | 6.3 | 2.39 | 55.6 |
| 2 | 1987-04-01 | 6.9 | 0.07 | 66.6 |
| 3 | 1987-05-01 | 7.4 | 0.87 | 71.8 |
| 4 | 1987-06-01 | 7.4 | 0.01 | 78.4 |
Checking autocorrelation of time dependent variables
The next step will determine if the time series sequence is autocorrelated. To ensure that our time series data can be modeled well, the strength of correlation of the variable with its past data must be estimated.
variables = ["AWND", "PRCP", "TAVG"]
for variable in variables:
plt.figure(figsize=(20, 2))
autocorr = aplot(final_df[variable], color="blue")
plt.title(variable)


The plots are showing a significant correlation of the data with its immediate time-lagged terms, and that it gradually decreases over time as the lag increases.
Creating dataset for prediction
Here, in the original dataset, the variable predict column of Average Temperature (TAVG) is populated with NaNs for the forecasting period of 2014-2015. This format is required for the model.predict() function in time series analysis, which will fill up the NaN values with forecasted temperatures.
predict_df = final_df.copy()
predict_df.loc[predict_df["DATE"] > "2013-12-01", "TAVG"] = None
predict_df.tail()| DATE | AWND | PRCP | TAVG | |
|---|---|---|---|---|
| 341 | 2015-07-01 | 8.1 | 0.43 | NaN |
| 342 | 2015-08-01 | 7.6 | 0.00 | NaN |
| 343 | 2015-09-01 | 5.8 | 0.12 | NaN |
| 344 | 2015-10-01 | 4.7 | 0.49 | NaN |
| 345 | 2015-11-01 | 3.6 | 1.74 | NaN |
Train - Test split of time series dataset
Out of these 27 years(1987-2015), 25 years of data is used for training the model, with the remaining 23 months (2014-2015) being used for forecasting and validation. As we are splitting timeseries data, we set shuffle=False to keep the sequence intact and we set a test size of 23 months for validation.
test_size = 23
train, test = train_test_split(final_df, test_size=test_size, shuffle=False)train| DATE | AWND | PRCP | TAVG | |
|---|---|---|---|---|
| 0 | 1987-02-01 | 5.8 | 1.36 | 52.7 |
| 1 | 1987-03-01 | 6.3 | 2.39 | 55.6 |
| 2 | 1987-04-01 | 6.9 | 0.07 | 66.6 |
| 3 | 1987-05-01 | 7.4 | 0.87 | 71.8 |
| 4 | 1987-06-01 | 7.4 | 0.01 | 78.4 |
| ... | ... | ... | ... | ... |
| 318 | 2013-08-01 | 7.2 | 0.00 | 83.0 |
| 319 | 2013-09-01 | 6.5 | 0.01 | 77.8 |
| 320 | 2013-10-01 | 3.4 | 0.03 | 66.6 |
| 321 | 2013-11-01 | 2.5 | 0.54 | 58.5 |
| 322 | 2013-12-01 | 2.2 | 0.15 | 47.4 |
323 rows × 4 columns
Time series model building
After the train and test sets are created, the training set is ready for modeling.
Data preprocessing
In this example, the dataset contains 'AWND' (Windspeed), 'PRCP' (Precipitation), and 'TAVG' (Average Air temperature) as time-dependent variables leading to a multivariate time series analysis at a monthly time scale. These variables are used to forecast the next 23 months of air temperature for the months after the last date in the training data, or, in other words, these multiple explanatory variables are used to predict the future values of the dependent air temperature variable.
Once the variables are identified, the preprocessing of the data is performed by the prepare_tabulardata method from the arcgis.learn module in the ArcGIS API for Python. This function takes either a non-spatial data frame, a feature layer, or a spatial data frame containing the dataset as input and returns a TabularDataObject that can be fed into the model. By default, prepare_tabulardata scales/normalizes the numerical columns in a dataset using StandardScaler.
The primary input parameters required for the tool are:
- input_features : Takes the spatially enabled dataframe as a feature layer in this model
- variable_predict : The field name of the forecasting variable
- explanatory_variables : A list of the field names that are used as time-dependent variables in multivariate time series
- index_field : The field name containing the timestamp that will be used as the index field for the data and to visualize values on the x-axis in the time series
data = prepare_tabulardata(
train,
variable_predict="TAVG",
explanatory_variables=["AWND", "PRCP"],
index_field="DATE",
seed=42,
)C:\Program Files\ArcGIS\Pro\bin\Python\envs\arcgispro-py3\lib\site-packages\arcgis\learn\_utils\tabular_data.py:936: UserWarning: Dataframe is not spatial, Rasters and distance layers will not work
# Visualize the entire timeseries data
data.show_batch(graph=True)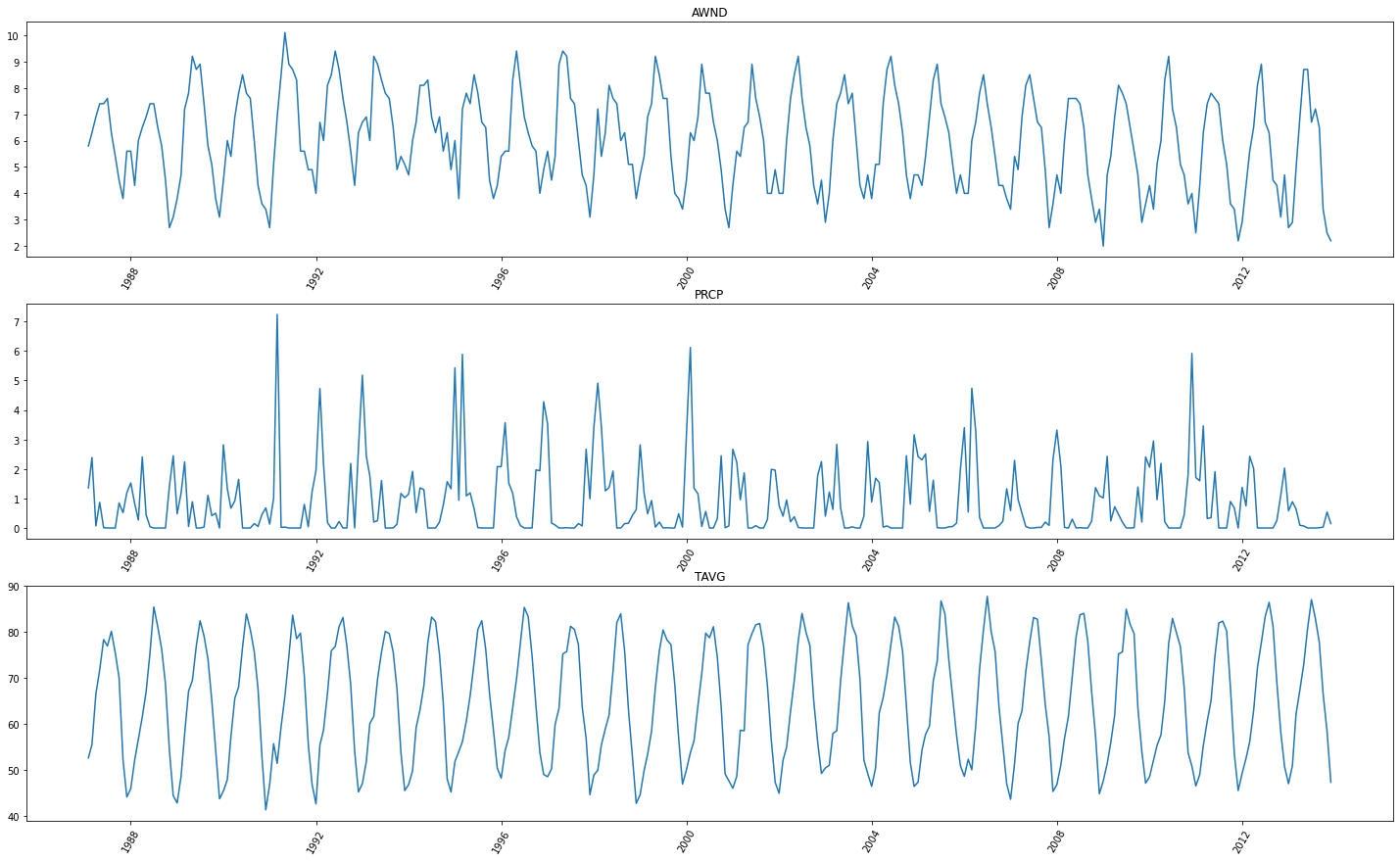
# Here sequence length is used as 12 which also indicates the seasonality of the data
seq_len = 12Next, we visualize the timeseries in batches. Here, we will pass the sequence length as the batch length.
data.show_batch(rows=4, seq_len=seq_len)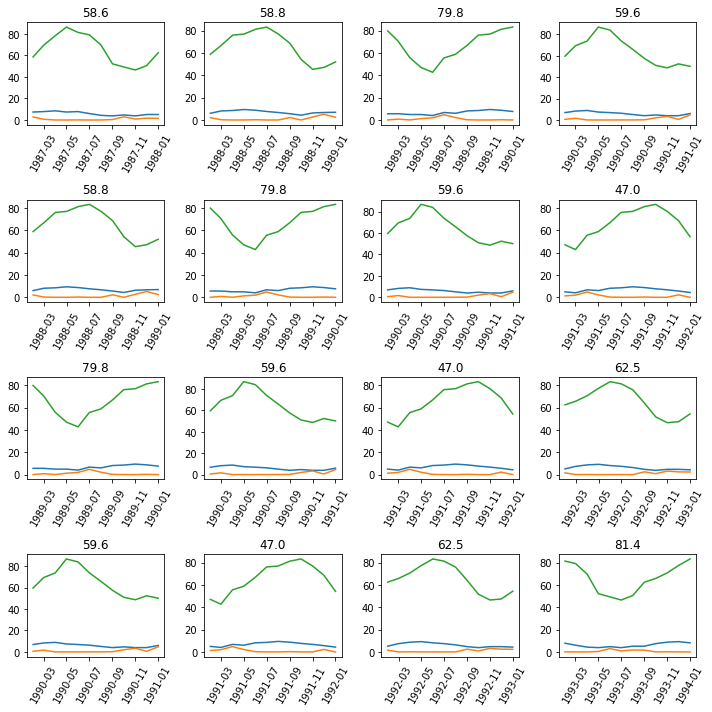
Model initialization
This is an important step for fitting a time series model. Here, along with the input dataset, the backbone for training the model and the sequence length are passed as parameters. Out of these three, the sequence length has to be selected carefully. The sequence length is usually the cycle of the data, which in this case is 12, as it is monthly data and the pattern repeats after 12 months. In model initialization, the data and the backbone are selected from the available set of InceptionTime, ResCNN, Resnet, and FCN.
tsmodel = TimeSeriesModel(data, seq_len=seq_len, model_arch="ResCNN")Learning rate search
Here, we find the optimal learning rate for training the model.
lr_rate = tsmodel.lr_find()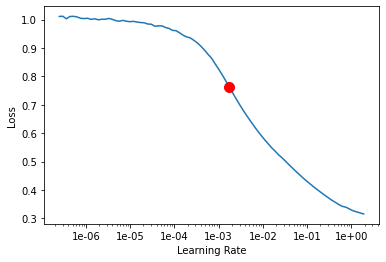
Model training
The model is now ready for training. To train the model, the model.fit method is used and is provided with the number of epochs for training and the learning rate suggested above as parameters:
tsmodel.fit(100, lr=lr_rate)| epoch | train_loss | valid_loss | time |
|---|---|---|---|
| 0 | 0.960341 | 0.327997 | 00:00 |
| 1 | 0.905986 | 0.398620 | 00:00 |
| 2 | 0.854629 | 0.495778 | 00:00 |
| 3 | 0.803305 | 0.601204 | 00:00 |
| 4 | 0.750918 | 0.714522 | 00:00 |
| 5 | 0.694405 | 0.837259 | 00:00 |
| 6 | 0.629638 | 0.899321 | 00:00 |
| 7 | 0.564060 | 0.799259 | 00:00 |
| 8 | 0.498104 | 0.516647 | 00:00 |
| 9 | 0.436980 | 0.270044 | 00:00 |
| 10 | 0.382555 | 0.127830 | 00:00 |
| 11 | 0.335652 | 0.072086 | 00:00 |
| 12 | 0.296507 | 0.011030 | 00:00 |
| 13 | 0.263554 | 0.007625 | 00:00 |
| 14 | 0.235444 | 0.007725 | 00:00 |
| 15 | 0.210686 | 0.016559 | 00:00 |
| 16 | 0.189255 | 0.008922 | 00:00 |
| 17 | 0.170306 | 0.004350 | 00:00 |
| 18 | 0.153841 | 0.010464 | 00:00 |
| 19 | 0.139377 | 0.015209 | 00:00 |
| 20 | 0.126539 | 0.004292 | 00:00 |
| 21 | 0.115118 | 0.005252 | 00:00 |
| 22 | 0.104859 | 0.002869 | 00:00 |
| 23 | 0.095638 | 0.002625 | 00:00 |
| 24 | 0.087301 | 0.006485 | 00:00 |
| 25 | 0.080027 | 0.009469 | 00:00 |
| 26 | 0.073334 | 0.009204 | 00:00 |
| 27 | 0.067324 | 0.005014 | 00:00 |
| 28 | 0.061931 | 0.003779 | 00:00 |
| 29 | 0.056923 | 0.003239 | 00:00 |
| 30 | 0.052320 | 0.003748 | 00:00 |
| 31 | 0.048077 | 0.002600 | 00:00 |
| 32 | 0.044202 | 0.004696 | 00:00 |
| 33 | 0.040764 | 0.005033 | 00:00 |
| 34 | 0.037607 | 0.001809 | 00:00 |
| 35 | 0.034591 | 0.002268 | 00:00 |
| 36 | 0.031892 | 0.002683 | 00:00 |
| 37 | 0.029392 | 0.002046 | 00:00 |
| 38 | 0.027079 | 0.003014 | 00:00 |
| 39 | 0.025031 | 0.002233 | 00:00 |
| 40 | 0.023200 | 0.003286 | 00:00 |
| 41 | 0.021619 | 0.004038 | 00:00 |
| 42 | 0.020044 | 0.002866 | 00:00 |
| 43 | 0.018576 | 0.002538 | 00:00 |
| 44 | 0.017208 | 0.002113 | 00:00 |
| 45 | 0.015948 | 0.003038 | 00:00 |
| 46 | 0.014801 | 0.001666 | 00:00 |
| 47 | 0.013740 | 0.005640 | 00:00 |
| 48 | 0.012854 | 0.001948 | 00:00 |
| 49 | 0.012011 | 0.003482 | 00:00 |
| 50 | 0.011200 | 0.001851 | 00:00 |
| 51 | 0.010443 | 0.003678 | 00:00 |
| 52 | 0.009682 | 0.002429 | 00:00 |
| 53 | 0.009051 | 0.002110 | 00:00 |
| 54 | 0.008452 | 0.002501 | 00:00 |
| 55 | 0.007954 | 0.002407 | 00:00 |
| 56 | 0.007382 | 0.001861 | 00:00 |
| 57 | 0.006923 | 0.002152 | 00:00 |
| 58 | 0.006464 | 0.002342 | 00:00 |
| 59 | 0.006101 | 0.001794 | 00:00 |
| 60 | 0.005727 | 0.001933 | 00:00 |
| 61 | 0.005591 | 0.003044 | 00:00 |
| 62 | 0.005265 | 0.004069 | 00:00 |
| 63 | 0.005186 | 0.002659 | 00:00 |
| 64 | 0.004908 | 0.002070 | 00:00 |
| 65 | 0.004728 | 0.002142 | 00:00 |
| 66 | 0.004427 | 0.001737 | 00:00 |
| 67 | 0.004143 | 0.002057 | 00:00 |
| 68 | 0.003877 | 0.001939 | 00:00 |
| 69 | 0.003609 | 0.001804 | 00:00 |
| 70 | 0.003400 | 0.001770 | 00:00 |
| 71 | 0.003187 | 0.001897 | 00:00 |
| 72 | 0.003073 | 0.001739 | 00:00 |
| 73 | 0.002866 | 0.001978 | 00:00 |
| 74 | 0.002682 | 0.001729 | 00:00 |
| 75 | 0.002523 | 0.001811 | 00:00 |
| 76 | 0.002354 | 0.001935 | 00:00 |
| 77 | 0.002253 | 0.001690 | 00:00 |
| 78 | 0.002108 | 0.001890 | 00:00 |
| 79 | 0.001960 | 0.002030 | 00:00 |
| 80 | 0.001826 | 0.001838 | 00:00 |
| 81 | 0.001734 | 0.001769 | 00:00 |
| 82 | 0.001704 | 0.001844 | 00:00 |
| 83 | 0.001645 | 0.001852 | 00:00 |
| 84 | 0.001591 | 0.001816 | 00:00 |
| 85 | 0.001580 | 0.001718 | 00:00 |
| 86 | 0.001504 | 0.001718 | 00:00 |
| 87 | 0.001406 | 0.001782 | 00:00 |
| 88 | 0.001502 | 0.001797 | 00:00 |
| 89 | 0.001413 | 0.001755 | 00:00 |
| 90 | 0.001378 | 0.001745 | 00:00 |
| 91 | 0.001311 | 0.001726 | 00:00 |
| 92 | 0.001237 | 0.001727 | 00:00 |
| 93 | 0.001171 | 0.001742 | 00:00 |
| 94 | 0.001100 | 0.001734 | 00:00 |
| 95 | 0.001056 | 0.001722 | 00:00 |
| 96 | 0.000998 | 0.001727 | 00:00 |
| 97 | 0.000968 | 0.001729 | 00:00 |
| 98 | 0.001004 | 0.001731 | 00:00 |
| 99 | 0.000939 | 0.001726 | 00:00 |
To check the quality of the trained model and whether the model needs more training, we generate a train vs validation loss plot below:
tsmodel.plot_losses()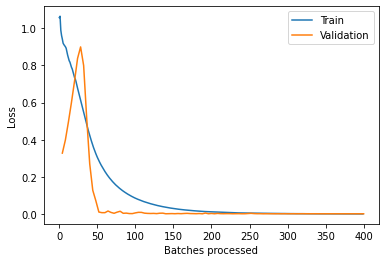
Next, the predicted values of the model and the actual values are printed for the training dataset.
tsmodel.show_results(rows=5)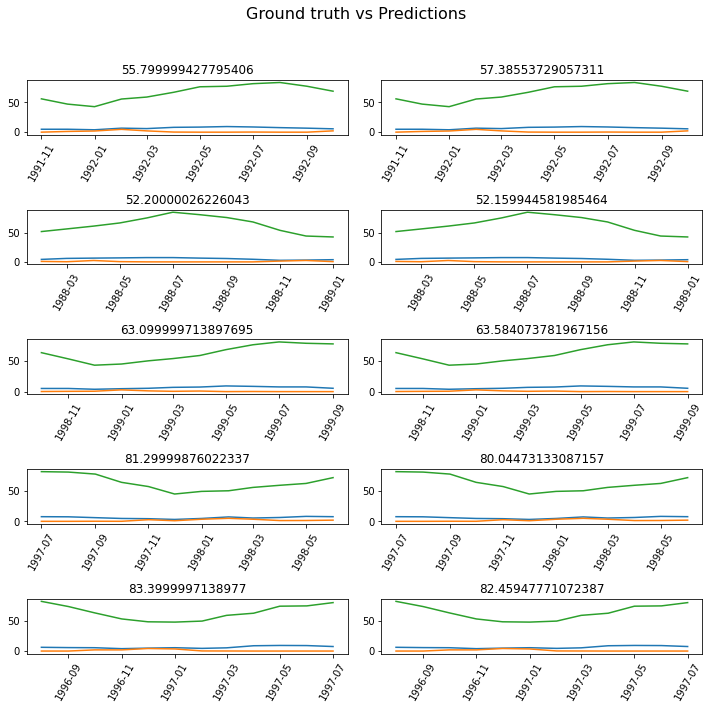
Air temperature forecast & validation
Forecasting using the trained TimeSeriesModel
During forecasting, the model uses the dataset prepared above with NaN values as input, with the prediction_type set as dataframe.
# Checking the input dataset
predict_df.tail(23)| DATE | AWND | PRCP | TAVG | |
|---|---|---|---|---|
| 323 | 2014-01-01 | 2.5 | 0.57 | NaN |
| 324 | 2014-02-01 | 4.9 | 2.11 | NaN |
| 325 | 2014-03-01 | 5.8 | 0.62 | NaN |
| 326 | 2014-04-01 | 6.9 | 0.74 | NaN |
| 327 | 2014-05-01 | 8.9 | 0.04 | NaN |
| 328 | 2014-06-01 | 8.1 | 0.00 | NaN |
| 329 | 2014-07-01 | 7.4 | 0.01 | NaN |
| 330 | 2014-08-01 | 6.7 | 0.00 | NaN |
| 331 | 2014-09-01 | 6.3 | 0.18 | NaN |
| 332 | 2014-10-01 | 4.5 | 0.50 | NaN |
| 333 | 2014-11-01 | 3.1 | 0.40 | NaN |
| 334 | 2014-12-01 | 4.0 | 2.30 | NaN |
| 335 | 2015-01-01 | 2.2 | 0.21 | NaN |
| 336 | 2015-02-01 | 3.8 | 1.13 | NaN |
| 337 | 2015-03-01 | 5.4 | 0.06 | NaN |
| 338 | 2015-04-01 | 6.9 | 1.25 | NaN |
| 339 | 2015-05-01 | 7.6 | 0.57 | NaN |
| 340 | 2015-06-01 | 7.6 | 0.01 | NaN |
| 341 | 2015-07-01 | 8.1 | 0.43 | NaN |
| 342 | 2015-08-01 | 7.6 | 0.00 | NaN |
| 343 | 2015-09-01 | 5.8 | 0.12 | NaN |
| 344 | 2015-10-01 | 4.7 | 0.49 | NaN |
| 345 | 2015-11-01 | 3.6 | 1.74 | NaN |
df_forecasted = tsmodel.predict(predict_df, prediction_type="dataframe")# Final forecasted result returned by the model
df_forecasted| DATE | AWND | PRCP | TAVG | TAVG_results | |
|---|---|---|---|---|---|
| 0 | 1987-02-01 | 5.8 | 1.36 | 52.7 | 52.700000 |
| 1 | 1987-03-01 | 6.3 | 2.39 | 55.6 | 55.600000 |
| 2 | 1987-04-01 | 6.9 | 0.07 | 66.6 | 66.600000 |
| 3 | 1987-05-01 | 7.4 | 0.87 | 71.8 | 71.800000 |
| 4 | 1987-06-01 | 7.4 | 0.01 | 78.4 | 78.400000 |
| ... | ... | ... | ... | ... | ... |
| 341 | 2015-07-01 | 8.1 | 0.43 | NaN | 84.969053 |
| 342 | 2015-08-01 | 7.6 | 0.00 | NaN | 81.919138 |
| 343 | 2015-09-01 | 5.8 | 0.12 | NaN | 77.078820 |
| 344 | 2015-10-01 | 4.7 | 0.49 | NaN | 69.666935 |
| 345 | 2015-11-01 | 3.6 | 1.74 | NaN | 58.852926 |
346 rows × 5 columns
Next, we format the results into actual vs predicted columns.
result_df = pd.DataFrame()
result_df["DATE"] = test["DATE"]
result_df["Airtemp_actual"] = test["TAVG"]
result_df["Airtemp_predicted"] = df_forecasted["TAVG_results"][-23:]
result_df = result_df.set_index(result_df.columns[0])
result_df| Airtemp_actual | Airtemp_predicted | |
|---|---|---|
| DATE | ||
| 2014-01-01 | 53.2 | 48.777484 |
| 2014-02-01 | 56.8 | 52.200898 |
| 2014-03-01 | 62.3 | 59.264070 |
| 2014-04-01 | 66.8 | 65.984249 |
| 2014-05-01 | 74.2 | 72.340793 |
| 2014-06-01 | 80.9 | 77.236778 |
| 2014-07-01 | 86.9 | 84.582398 |
| 2014-08-01 | 84.4 | 81.742578 |
| 2014-09-01 | 80.7 | 76.948140 |
| 2014-10-01 | 72.0 | 67.554652 |
| 2014-11-01 | 57.7 | 58.481853 |
| 2014-12-01 | 51.9 | 47.955960 |
| 2015-01-01 | 49.0 | 47.175748 |
| 2015-02-01 | 57.0 | 50.230618 |
| 2015-03-01 | 64.0 | 56.937533 |
| 2015-04-01 | 64.3 | 64.488977 |
| 2015-05-01 | 68.5 | 71.976515 |
| 2015-06-01 | 81.9 | 78.548443 |
| 2015-07-01 | 83.1 | 84.969053 |
| 2015-08-01 | 82.4 | 81.919138 |
| 2015-09-01 | 78.7 | 77.078820 |
| 2015-10-01 | 71.3 | 69.666935 |
| 2015-11-01 | 52.0 | 58.852926 |
Estimate model metrics for validation
The accuracy of the forecasted values is measured by comparing the forecasted values against the actual values for the 23 months chosen for testing.
r2 = r2_score(result_df["Airtemp_actual"], result_df["Airtemp_predicted"])
mse = metrics.mean_squared_error(
result_df["Airtemp_actual"], result_df["Airtemp_predicted"]
)
rmse = metrics.mean_absolute_error(
result_df["Airtemp_actual"], result_df["Airtemp_predicted"]
)
print(
"RMSE: ",
round(np.sqrt(mse), 4),
"\n" "MAE: ",
round(rmse, 4),
"\n" "R-Square: ",
round(r2, 2),
)RMSE: 3.661 MAE: 3.1054 R-Square: 0.91
A considerably high r-square value of .91 indicates a high similarity between the forecasted values and the actual values. Furthermore, the RMSE error of 3.661 is quite low, indicating a good fit by the model.
Result visualization
Finally, the actual and forecasted values are plotted to visualize their distribution over the validation period, with the orange line representing the forecasted values and the blue line representing the actual values.
plt.figure(figsize=(20, 5))
plt.plot(result_df)
plt.ylabel("Air Temperature")
plt.legend(result_df.columns.values, loc="upper right")
plt.title("Forecasted Air Temperature")
plt.show()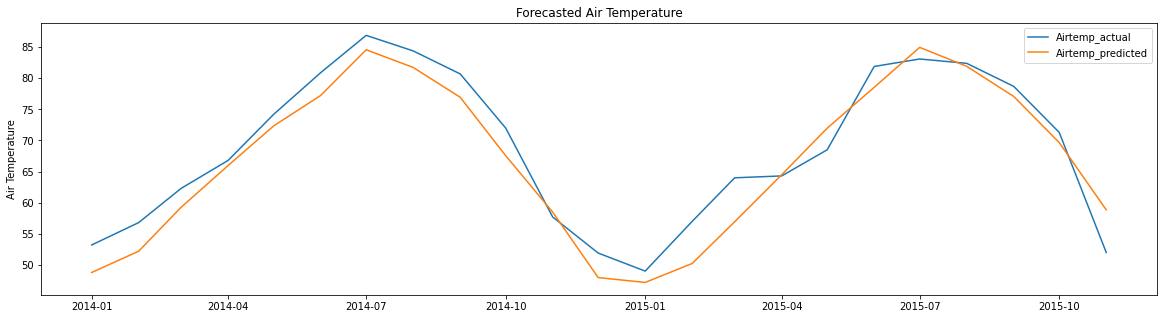
Conclusion
The study conducted a multivariate time series analysis using the Deep learning TimeSeriesModel from the arcgis.learn library and forecasted the monthly Air temperature for a station in California. The model was trained with 25 years of data (1987-2013) that was used to forecast a period of 2 years (2014-2015) with high accuracy. The independent variables were wind speed and precipitation. The methodology included preparing a times series dataset using the prepare_tabulardata() method, followed by modeling, predicting, and validating the test dataset. Usually, time series modeling requires fine-tuning several hyperparameters for properly fitting the data, most of which has been internalized in this Model, leaving the user responsible for configuring only a few significant parameters, like the sequence length.
Summary of methods used
| Method | Description | Examples |
|---|---|---|
| prepare_tabulardata | prepare data including imputation, scaling and train-test split | prepare data ready for fitting a Timeseries Model |
| model.lr_find() | finds an optimal learning rate | finalize a good learning rate for training the Timeseries model |
| TimeSeriesModel() | Model Initialization by selecting the TimeSeriesModel algorithm to be used for fitting | Selected Timeseries algorithm from Fastai time series regression can be used |
| model.fit() | trains a model with epochs & learning rate as input | training the Timeseries model with suitable input |
| model.predict() | predicts on a test set | forecast values using the trained models on the test input |
References
-
Jenny Cifuentes et.al., 2020. "Air Temperature Forecasting Using Machine Learning Techniques: A Review" https://doi.org/10.3390/en13164215
-
Xuejie, G. et.al., 2001. "Climate change due to greenhouse effects in China as simulated by a regional climate model" https://doi.org/10.1007/s00376-001-0036-y
-
"gsom-gsoy_documentation" https://www1.ncdc.noaa.gov/pub/data/cdo/documentation/gsom-gsoy_documentation.pdf
-
"Prediction task with Multivariate Time Series and VAR model" https://towardsdatascience.com/prediction-task-with-multivariate-timeseries-and-var-model-47003f629f9
Data resources
| Dataset | Source | Link |
|---|---|---|
| Global Summary of the Month | NOAA Climate Data Online | https://www.ncdc.noaa.gov/cdo-web/search |