- URL:
- https://<root>/<serviceName>/RasterAnalysisTools/GPServer/ZonalStatisticsAsTable
- Methods:
GET- Version Introduced:
- 10.8.1
Description
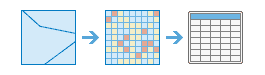
The Zonal task summarizes the cells of a raster within the boundaries of zones defined by another dataset.
Zonal uses two layers, one that defines specific zones and another that defines the value of each location across the whole area, and calculates summary statistic for the values that fall within each particular area. The layer that defines the areas, input, is a raster or feature dataset that defines the boundaries of each zone for which a summary values will be calculated. If the zone layer is a raster, it must have an integer data type. If the zone is a feature layer, it can contain overlapping polygons, where the zonal analysis will be performed for each individual feature. The area defining the values, input, is a raster dataset that records the value of a particular property at each location.
The statistic can report such properties as the sum of all the values in each area, the maximum value, or the average value. The statistic value can be calculated based on a mathematical function, the result of a sorting operation on the values, or an indication of the frequency values.
The following are example applications of Zonal:
- Given a layer of state boundaries and the distribution of mean precipitation over the continental United States, calculate the state-wise distribution of extreme rain events using a list of percentile values.
- Given a layer of overlapping ecological zones and a raster layer of soil moisture, calculate all supported statistics within each zone to relate zones with soil moisture availability.
Request parameters
| Parameter | Details |
|---|---|
| The layer that defines the boundaries of the zones. Syntax: This parameter can have either a raster input or a feature input. For raster input, this parameter can be specified as a portal item ID, a URL to a raster image service layer, a cloud raster dataset, or a shared raster dataset. For feature input, this parameter can be specified as either a URL to a feature service layer or a feature collection. Raster input examples: Feature input examples: |
| The raster layer that will be summarized by the zones defined by the Syntax: This parameter can be specified as a portal item ID, a URL to a raster image service layer, a cloud raster dataset, or a shared raster dataset. Examples: |
| The output table feature service name that will be created. You can specify the name, or you can create an empty service using Portal Admin Sharing API and use the return JSON object as input to this parameter. Syntax: A JSON object describes the name of the output or the output table. Output name example: Output table examples: |
| A field on the It can be an integer or a string field of the zone dataset. Example: |
| Specify whether NoData in the raster layer to summarize will influence the results of the areas they fall within. Syntax: A Boolean value as either
Example: |
| The statistical summary type that will be calculated for the cells within each zone of the feature in the Syntax: The input can be one of the following:
Example: |
|
Specifies the percentile value to calculate. The default is 90, for the 90th percentile. The values can range from 0 to 100. The 0th percentile is essentially equivalent to the minimum statistic, and the 100th percentile is equivalent to the maximum. A value of 50 will produce approximately the same result as the median statistic. This parameter is only supported if the A single or a list of double-precision floating-point values that can range from 0 to 100. Example: |
|
Specifies how the input rasters will be processed if they are multidimensional. Syntax: A Boolean value as either
Example: |
|
Specifies the method of percentile interpolation to be used when the number of values from the input raster to be calculated is even.
Example: |
|
Specifies how the statistics type will be calculated. Syntax: A Boolean value as either
Example: |
|
Specifies the highest possible value (upper bound) in the cyclic data. It is a positive number, with a default value of 360. This value also represents the same quantity as the lowest possible value (lower bound). This parameter is applicable only when circular statistics are calculated. |
|
Contains additional settings that affect task processing. This task has the following settings:
|
|
The response format. The default response format is Values: |
Response
When you submit a request, the task assigns a unique job ID for the transaction.
{
"jobId": "<unique job identifier>",
"jobStatus": "<job status>"
}After the initial request is submitted, you can use the job to periodically check the status of the job and messages as described in Checking job status. Once the job has successfully completed, you use the job to retrieve the results. To track the status, you can make a request of the following form:
https://<raster analysis tools url>/ZonalStatisticsAsTable/jobs/<jobId>When the status of the job request is esri , you can access the results of the analysis by making a request of the following form:
https://<raster analysis tools url>/ZonalStatisticsAsTable/jobs/<jobId>/results/outputTableExample usage
The following is a sample request URL for Zonal :
https://services.myserver.com/arcgis/rest/services/System/RasterAnalysisTools/GPServer/ZonalStatisticsAsTable/submitJobJSON Response syntax
The response returns the output output parameter, which has properties for parameter name, data type, and value. The content of value is always the output table item and the feature service URL.
{
"paramName": <parameter name>,
"dataType": "GPString",
"value": {
"itemId": <item Id>,
"url": <URL>
}
}JSON Response example
{
"paramName": "outputTable",
"dataType": "GPString",
"value": {
"url": "https://<server name>/server/rest/services/Hosted/<service name>/FeatureServer/0",
"itemId": "351fe8441a1a436d8001124487b02550"
}
}