These tools are used for the day-to-day management of geographic and tabular data.
copy_to_data_store copies data to your ArcGIS Data Store and creates a layer in your web GIS.
append_data
-
arcgis.geoanalytics.manage_data.append_data(input_layer, append_layer, field_mapping=None, gis=None, future=False) Only available at ArcGIS Enterprise 10.6.1 and later.
The Append Data task appends tabular, point, line, or polygon data to an existing layer. The input layer must be a hosted feature layer. The tool will add the appended data as rows to the input layer. No new output layer is created.
Parameter
Description
input_layer
Required
FeatureLayer. The table, point, line or polygon features.append_layer
Required
FeatureLayer. The table, point, line, or polygon features to be appended to theinput_layer. To append geometry, theappend_layermust have the same geometry type as theinput_layer. If the geometry types are not the same, theappend_layergeometry will be removed and all other matching fields will be appended. The geometry of theinput_layerwill always be maintained.field_mapping
Defines how the fields in append_layer are appended to the input_layer.
The following are set by default:
All
append_layerfields that matchinput_layerschema will be appendedFields that exist in the
input_layerand not in theappend_layerwill be appended with null valuesFields that exist in the
append_layerand not in theinput_layerwill not be appended
Optionally, choose how
input_layerfields will be appended from the following:AppendField- Matches theinput_layerfield with anappend_layerfield of a different name. Field types must match.Expression- Calculates values for the resulting field. Values are calculated using Arcade expressions. To assign null values, usenull.
The following code snippet appends Average_Sales to Mean_Sales, calculates an expression of WeeklyRate multiplied by 1.5 to append the values for Bonus, and sets a value of
nullfor appended features in Errors.#Usage Example: >>> from arcgis.geoanalytics.manage_data import append_data >>> resp = append_data(input_layer=flyr_base, append_layer=flyr_append, field_mapping= [ {"inputLayerField": "Mean_Sales", "mappingType": "AppendField", "mappingValue": "Average_Sales"}, {"inputLayerField": "Bonus", "mappingType": "Expression", "mappingValue": "$feature['WeeklyRate'] * 1.5"}, {"inputLayerField": "Errors", "mappingType": "Expression", "mappingValue": "null"} ])
gis
Optional
GISon which this tool runs. If not specified, the active GIS is used.future
Optional boolean. If
True, a future object will be returned and the process will not wait for the task to complete. The default isFalse, which means wait for results.- Returns
True or an error
calculate_fields
-
arcgis.geoanalytics.manage_data.calculate_fields(input_layer, field_name, data_type, expression, track_aware=False, track_fields=None, time_boundary_split=None, time_split_unit=None, time_reference=None, output_name=None, gis=None, context=None, future=False) 
The
calculate_fieldstask works with a layer to create and populate a new field. The output is a new feature layer, that is the same as the input features, with the additional field added.Parameter
Description
input_layer
Required layer. The input features that will have a field added and calculated. See Feature Input.
field_name
Required string. A string representing the name of the new field. If the name already exists in the dataset, then a numeric value will be appended to the field name.
data_type
Required string. The type for the new field.
Choice list:
DateDoubleIntegerString
expression
Required string. An Arcade expression used to calculate the new field values. You can use any of the Date, Logical, Mathematical, or Text functions available with Arcade.
See Arcade Function Reference for details.
track_aware
Optional boolean. Boolean value denoting if the expression is track aware.
The default value is ‘False’.
track_fields (Required if trackAware is True)
Optional string. The fields used to identify distinct tracks. There can be multiple track_fields. track_fields are only required when
track_awareis True.time_boundary_split
Optional integer. A time boundary allows your to analyze values within a defined time span. For example, if you use a time boundary of 1 day, starting on January 1st, 1980 tracks will be analyzed 1 day at a time. The time boundary parameter was introduced in ArcGIS Enterprise 10.7.
The time boundary parameters are only applicable if the analysis is
track_aware. Thetime_boundary_splitparameter defines the scale of the time boundary. In the case above, this would be 1.See the portal documentation for this tool to learn more.
time_split_unit
Optional string. The unit to detect an incident is time_boundary_split is used.
Choice list:
YearsMonthsWeeksDaysHoursMinutesSecondsMilliseconds
time_reference
Optional datetime.datetime. The starting date/time where analysis will begin from.
output_name
Optional string, The task will create a feature service of the results. You define the name of the service.
gis
Optional
GISon which this tool runs. If not specified, the active GIS is used.context
Optional dict. The context parameter contains additional settings that affect task execution. For this task, there are four settings:
extent- A bounding box that defines the analysis area. Only those features that intersect the bounding box will be analyzed.processSR- The features will be projected into this coordinate system for analysis.outSR- The features will be projected into this coordinate system after the analysis to be saved. The output spatial reference for the spatiotemporal big data store is always WGS84.dataStore- Results will be saved to the specified data store. For ArcGIS Enterprise, the default is the spatiotemporal big data store.
future
Optional boolean. If
True, a future object will be returned and the process will not wait for the task to complete. The default isFalse, which means wait for results.- Returns
# Usage Example: To find maximum of the two attributes of an input layer. result = calculate_fields(input_layer=lyr, field_name="avg", data_type="Double", expression='max($feature["InputValue"],$feature["Value2"])')
clip_layer
-
arcgis.geoanalytics.manage_data.clip_layer(input_layer, clip_layer, output_name=None, gis=None, context=None, future=False) 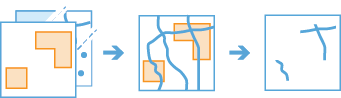
clip_layerfeatures from one layer to the extent of a boundary layer. Use this tool to cut out a piece of one feature class using one or more of the features in another feature class as a cookie cutter. This is particularly useful for creating a new feature layers - also referred to as study area or area of interest (AOI) - that contains a geographic subset of the features in another, larger feature class.Only available at ArcGIS Enterprise 10.7 and later.
Parameter
Description
input_layer
Required feature layer. The point, line, or polygon features that will be clipped to the areas of
clip_layerfeatures. See Feature Input.clip_layer
Required feature layer. The polygon features that define the areas to which
input_layerfeatures will be clipped. See Feature Input.output_name
Optional string. The task will create a feature service of the results. You define the name of the service.
context
Optional strin. The context parameter contains additional settings that affect task execution. For this task, there are four settings:
extent- A bounding box that defines the analysis area. Only those features that intersect the bounding box will be analyzed.processSR- The features will be projected into this coordinate system for analysis.outSR- The features will be projected in this coordinate system after the analysis to be saved. The output spatial reference for the spatiotemporal big data store is always WGS84.dataStore- Results will be saved to the specified data store. For ArcGIS Enterprise, the default is the spatiotemporal big data store.
gis
Optional
GISon which the analysis will take place.future
Optional boolean. If
True, a future object will be returned and the process will not wait for the task to complete. The default isFalse, which means wait for results.- Returns
# Usage Example: To clip the buffered area in the shape of Capitol Hill boundary. clipped = clip_layer(input_layer=buffer, clip_layer=boundary, output_name="clipped_buffer", context={"extent":{'xmin': -77.50941999999998,'ymin': 38.389560000000074,'xmax': -76.50941999999998,'ymax': 39.389560000000074,"spatialReference":{"wkid":102100,"latestWkid":3857}}})
copy_to_data_store
-
arcgis.geoanalytics.manage_data.copy_to_data_store(input_layer, output_name=None, gis=None, context=None, future=False) 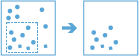
The
copy_to_data_storetask takes an input layer and copies it to a data store. Data is copied to ArcGIS Data Store, configured as either a relational or spatiotemporal big data store.For example
Copy a collection of .csv files in a big data file share to the spatiotemporal data store for visualization.
Copy the features in the current map extent that are stored in the spatiotemporal data store to the relational data store.
This tool will take an input layer and copy it to a data store. Data will be copied to the ArcGIS Data Store and will be stored in your relational or spatiotemporal data store.
For example, you could copy features that are stored in a big data file share to a relational data store and specify that only features within the current map extent will be copied. This would create a hosted feature service with only those features that were within the specified map extent.
Parameter
Description
input_layer
Required layer. The table, point, line, or polygon features that will be copied. See Feature Input.
output_name
Optional string. The task will create a feature service of the results. You define the name of the service.
gis
Optional GIS. The GIS on which this tool runs. If not specified, the active GIS is used.
context
Optional string. The context parameter contains additional settings that affect task execution. For this task, there are five settings:
extent- A bounding box that defines the analysis area. Only those features that intersect the bounding box will be analyzed.processSR- The features will be projected into this coordinate system for analysis.outSR- The features will be projected into this coordinate system after the analysis to be saved. The output spatial reference for the spatiotemporal big data store is always WGS84.dataStore- Results will be saved to the specified data store. For ArcGIS Enterprise, the default is the spatiotemporal big data store.defaultAggregationStyles- If set toTrue, results will have square, hexagon, and triangle aggregation styles enabled on results map services.
future
Optional boolean. If
True, a future object will be returned and the process will not wait for the task to complete. The default isFalse, which means wait for results.- Returns
result_layer : Output Features as
FeatureLayer.
# Usage Example: To copy input layer to a data store. copy_result = copy_to_data_store(input_layer=earthquakes, output_name="copy earthquakes data")
dissolve_boundaries
-
arcgis.geoanalytics.manage_data.dissolve_boundaries(input_layer, dissolve_fields=None, summary_fields=None, multipart=False, output_name=None, gis=None, context=None, future=False) 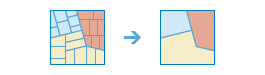
The
dissolve_boundariestask finds polygons that intersect or have the same field values and merges them together to form a single polygon.Example:
A city council wants to control liquor sales by refusing new licenses to stores within 1,000 feet of schools, libraries, and parks. After creating a 1,000-foot buffer around the schools, libraries, and parks, the buffered layers can be joined together and the boundaries can be dissolved to create a single layer of restricted areas.
Note
Only available at ArcGIS Enterprise 10.7 and later.
Parameter
Description
input_layer
Required layer. The layer containing polygon features that will be dissolved. See Feature Input.
dissolve_fields
Optional string. A comma seperated list of strings for each field that you want to dissolve on.One or more fields in the
input_layerthat determine how polygons are merged based on field value.If you don’t specify fields, polygons that intersect will be dissolved into one polygon by default.
If you do specify fields, polygons that share the same value for each of the specified fields will be dissolved into one polygon.
summary_fields
Optional list of dicts. A list of field names and statistical summary types you want to calculate. Note that the count is always returned. By default, all statistics are returned.
Syntax:
[{"statisticType" : "<stat>", "onStatisticField" : "<field name>"}]onStatisticField is the name of the field in the input point layer to calculate the statistic.
statisticType is one of the following for numeric fields:
Count- Totals the number of values of all the points in each polygon.Sum- Adds the total value of all the points in each polygon.Mean- Calculates the average of all the points in each polygon.Min- Finds the smallest value of all the points in each polygon.Max- Finds the largest value of all the points in each polygon.Range- Finds the difference between the Min and Max values.Stddev- Finds the standard deviation of all the points in each polygon.Var- Finds the variance of all the points in each polygon.
statisticType is one of the following for string fields:
Count- Totals the number of strings for all the points in each polygon.Any- Returns a sample string of a point in each polygon.
# Example >>> summary_fields = [{"statisticType" : "Sum", "onStatisticField" : "quadrat_area_km2"}, {"statisticType" : "Mean", "onStatisticField" : "soil_depth_cm"}, {"statisticType" : "Any", "onStatisticField" : "quadrat_desc"}]
multipart
Optional boolean. If
True, the output service can contain multipart features. IfFalse, the output service will only contain single-part features, and individual features will be created for each part.The default value is
False.output_name
Optional string. The task will create a feature service of the results. You define the name of the service.
gis
Optional
GISon which the analysis will take place.context
Optional dict. The context parameter contains additional settings that affect task execution. For this task, there are five settings:
extent- A bounding box that defines the analysis area. Only those features that intersect the bounding box will be analyzed.processSR- The features will be projected into this coordinate system for analysis.outSR- The features will be projected into this coordinate system after the analysis to be saved. The output spatial reference for the spatiotemporal big data store is always WGS84.dataStore- Results will be saved to the specified data store. For ArcGIS Enterprise, the default is the spatiotemporal big data store.defaultAggregationStyles- If set to true, results will have square, hexagon, and triangle aggregation styles enabled on results map services.
future
Optional boolean. If
True, a future object will be returned and the process will not wait for the task to complete. The default isFalse, which means wait for results.- Returns
# Usage Example: This example dissolves boundaries of soil areas in Nebraska if they have # the same solubility. For dissolved features, it calculates the sum of the quadrat area, # the mean soil depth, and an example of the quadrat description. arcgis.env.out_spatial_reference = 3310 arcgis.env.output_datastore= "relational" arcgis.env.defaultAggregations= True summary_fields = [{"statisticType" : "Sum", "onStatisticField" : "quadrat_area_km2"}, {"statisticType" : "Mean", "onStatisticField" : "soil_depth_cm"}, {"statisticType" : "Any", "onStatisticField" : "quadrat_desc"}] dissolve_result = dissolve_boundaries(input_layer=study_area_lyr, dissolve_fields="soil_suitability", summary_fields=summary_fields, multipart=True, output_name="Soil_Suitability_dissolved")
merge_layers
-
arcgis.geoanalytics.manage_data.merge_layers(input_layer, merge_layer, merge_attributes=None, output_name=None, gis=None, context=None, future=False) 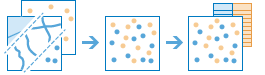
The
merge_layerstask combines two feature layers to create a single output layer. The tool requires that both layers have the same geometry type (tabular, point, line, or polygon). If time is enabled on one layer, the other must also be time enabled and have the same time type (instant or interval). The result will always contain all fields from the input layer. All fields from the merge layer will be included by default, or you can specify custom merge rules to define the resulting schema. For example:I have three layers for England, Wales, and Scotland and I want a single layer of Great Britain. I can use Merge Layers to combine the areas and maintain all fields from each area.
I have two layers containing parcel information for contiguous townships. I want to join them together into a single layer, keeping only the fields that have the same name and type in the two layers.
Note
Only available at ArcGIS Enterprise 10.7 and later.
Parameter
Description
input_layer
Required layer. The table, point, line, or polygon features to merge with the
merge_layerparameter. All fields ininput_layerwill be included in the result layer. See Feature Input.merge_layer
Required layer. The point, line, or polygon features to merge with the
input_layer. Themerge_layermust contain the same geometry type (tabular, point, line, or polygon) and the same time type (none, instant, or interval) as theinput_layer. All fields in themerge_layerwill be included in the result layer by default or you can definemerge_attributesto customize the resulting schema. See Feature Input.merge_attributes
Optional list of dicts. Defines how the fields in
merge_layerwill be modified. By default, all fields from both inputs will be included in the output layer.If a field exists in one layer but not the other, the output layer will still contain the field. The output field will contain null values for the input features that did not have the field. For example, if the
input_layercontains a field named TYPE but themerge_layerdoes not contain TYPE, the output will contain TYPE, but its values will be null for all the features copied from themerge_layer.You can control how fields in the
merge_layerare written to the output layer using the following merge types that operate on a specifiedmerge_layerfield:Remove- The field in themerge_layerwill be removed from the output layer.Rename- The field in themerge_layerwill be renamed in the output layer. You cannot rename a field in themerge_layerto a field in theinput_layer. If you want to make field names equivalent, use Match.Match- A field in the merge_layer is made equivalent to a field in theinput_layerspecified bymerge_layer. For example, the input_layer has a field named CODE and the merge_layer has a field named STATUS. You can match STATUS to CODE, and the output will contain the CODE field with values of the STATUS field used for features copied from the merge_layer. Type casting is supported (for example, double to integer, integer to string) except for string to numeric.
# Example: >>> merge_attributes = [{"mergeLayerField": "Mean_Sales", "mergeType": "Match", "mergeValue": "Average_Sales"}, {"mergeLayerField": "Bonus", "mergeType": "Remove",}, {"mergeLayerField": "Field4", "mergeType": "Rename", "mergeValue": "Errors"}]
output_name
Optional string. The task will create a feature service of the results. You define the name of the service.
gis
Optional
GISon which the analysis will take place.context
Optional dict. The context parameter contains additional settings that affect task execution. For this task, there are five settings:
extent- A bounding box that defines the analysis area. Only those features that intersect the bounding box will be analyzed.processSR- The features will be projected into this coordinate system for analysis.outSR- The features will be projected into this coordinate system after the analysis to be saved. The output spatial reference for the spatiotemporal big data store is always WGS84.dataStore- Results will be saved to the specified data store. For ArcGIS Enterprise, the default is the spatiotemporal big data store.defaultAggregationStyles- If set toTrue, results will have square, hexagon, and triangle aggregation styles enabled on results map services.
future
Optional boolean. If
True, a GPJob is returned instead of results. The GPJob can be queried on the status of the execution.The default value is
False.- Returns
# Usage Example: To merge census blocks from two states into one output layer. merge_result = merge_layers(input_layer=il_block, merge_layer=wi_block, merge_attributes=[{"mergeLayerField" : "State_Code", "mergeType" : "Match", "mergeValue" : "statecode"}], output_name="IL_WI_Census_Blocks")
overlay_data
-
arcgis.geoanalytics.manage_data.overlay_data(input_layer, overlay_layer, overlay_type='intersect', output_name=None, gis=None, include_overlaps=True, context=None, future=False) 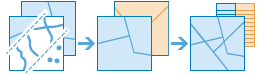
The
overlay_datatask combines two or more layers into one single layer. You can think of overlay as peering through a stack of maps and creating a single map containing all the information found in the stack. Overlay is used to answer one of the most basic questions of geography: What is on top of what? The following are examples:What parcels are within the 100-year floodplain? (“Within” is another way of saying “on top of.”)
What land use is within what soil type?
What mines are within abandoned military bases?
Note
Only available at ArcGIS Enterprise 10.6.1 and later.
Parameter
Description
input_layer
Required layer. The point, line, or polygon features that will be overlaid with the
overlay_layerfeatures. See Feature Input.overlay_layer
Required layer. The features that will be overlaid with the
input_layerfeatures.overlay_type
optional string. The type of overlay to be performed.
Choice list: [‘intersect’, ‘erase’, ‘union’, ‘identity’, ‘symmetricaldifference’]

intersectComputes a geometric intersection of the input layers. Features or portions of features that overlap in both the
input_layerandoverlay_layerlayers will be written to the output layer.Point — Point, Line, Polygon
Line — Point, Line, Polygon
Polygon— Point, Line, Polygon

eraseOnly those features or portions of features in the
overlay_layerthat are not within the features in theinput_layerlayer are written to the output.Point — Point
Line — Line
Polygon — Polygon

unionComputes a geometric union of the
input_layerandoverlay_layer. All features and their attributes will be written to the layer.Polygon — Polygon

identityComputes a geometric intersection of the input features and identity features. Features or portions of features that overlap in both
input_layerandoverlay_layerwill be written to the output layer.Point — Point, Polygon
Line — Line, Polygon
Polygon— Polygon

symmetricaldifferenceFeatures or portions of features in the
input_layerandoverlay_layerthat do not overlap will be written to the output layer.Point — Point
Line — Line
Polygon— Polygon
include_overlaps
Optional boolean. Determines whether input features in the same dataset contain overlapping features. The default is True. Change this parameter to False if you don’t want self-intersecting features for the input layer or the overlay layer. Setting this to False will also improve performance.
For 10.6 and 10.6.1, this parameter is only used when overlay_type` is
intersectFor 10.7 or later, the parameter is always True.
The default value is
True.output_name
Optional string. The task will create a feature service of the results. You define the name of the service.
gis
Optional
GISon which the analysis will take place.context
Optional dict. The context parameter contains additional settings that affect task execution. For this task, there are four settings:
extent- A bounding box that defines the analysis area. Only those features that intersect the bounding box will be analyzed.processSR- The features will be projected into this coordinate system for analysis.outSR- The features will be projected into this coordinate system after the analysis to be saved. The output spatial reference for the spatiotemporal big data store is always WGS84.dataStore- Results will be saved to the specified data store. For ArcGIS Enterprise, the default is the spatiotemporal big data store.
future
Optional boolean. If
True, a GPJob is returned instead of results. The GPJob can be queried on the status of the execution.The default value is
False.- Returns
# Usage Example: To find the intersecting areas between watersheds and grazing land in Missouri. overlay_result = manage_data.overlay_data(input_layer=grazing_land, overlay_layer=watersheds_layer, overlay_type="Intersect", output_name="Watershed_intersections")
run_python_script
-
arcgis.geoanalytics.manage_data.run_python_script(code, layers=None, gis=None, context=None, future=False, parameters=None, param_as_input=False) The
run_python_scriptmethod executes a Python script on your ArcGIS GeoAnalytics Server site. In the script, you can create an analysis pipeline by chaining together multiple GeoAnalytics Tools without writing intermediate results to a data store. You can also use other Python functionality in the script that can be distributed across your GeoAnalytics Server.For example, suppose that each week you receive a new dataset of vehicle locations containing billions of point features. Each time you receive a new dataset, you must perform the same workflow involving multiple GeoAnalytics Tools to create an information product that you share within your organization. This workflow creates several large intermediate layers that take up lots of space in your data store. By scripting this workflow in Python and executing the code in the Run Python Script task, you can avoid creating these unnecessary intermediate layers, while simplifying the steps to create the information product.
When you use
run_python_script, the Python code is executed on your GeoAnalytics Server. The script runs with the Python 3.6 environment that is installed with GeoAnalytics Server, and all console output is returned as job messages. Some Python modules can be used in your script to execute code across multiple cores of one or more machines in your GeoAnalytics Server using Spark 2.2.0(the compute platform that distributes analysis for GeoAnalytics Tools).A geoanalytics module is available and allows you to run GeoAnalytics Tools in the script. This package is imported automatically when you use Run Python Script.
To interact directly with Spark in the Run Python Script task, use the pyspark module, which is imported automatically when you run the task. The pyspark module is the Python API for Spark and provides a collection of distributed analysis tools for data management, clustering, regression, and more that can be called in Run Python Script and run across your GeoAnalytics Server.
When using the geoanalytics and pyspark packages, most functions return analysis results in memory as Spark DataFrames. Spark data frames can be written to a data store or used in the script. This allows for the chaining together of multiple geoanalytics and pyspark tools, while only writing out the final result to a data store, eliminating the need to create any intermediate result layers.
For advanced users, an instance of SparkContext is instantiated automatically as sc and can be used in the script to interact with Spark. This allows for the execution of custom distributed analysis across your GeoAnalytics Server.
It is recommended that you use an integrated development environment (IDE) to write your Python script, and copy the script text into the Run Python Script tool. This makes it easier to identify syntax errors and typos prior to running your script. It is also recommended that you run your script using a small subset of the input data first to verify that there are no logic errors or exceptions. You can use the Describe Dataset task to create a sample layer for this purpose.
code
Required string. The Python script that will run on your GeoAnalytics Server. This must be the full script as a string.
The layers provided in inputLayers can be accessed in the script using the layers object. To learn more, see Reading and writing layers in pyspark.
GeoAnalytics Tools can be accessed with the geoanalytics object, which is instantiated in the script environment automatically. To learn more, see Using GeoAnalytics Tools in Run Python Script.
For a collection of example scripts, see Examples: Scripting custom analysis with the Run Python Script task.
layers
Optional list. A list of
Feature Layersto operate on. See Feature Input.gis
optional
GISon which the analysis will take place.context
Optional dict. This parameter is not used by the
run_python_scripttool.To control the output data store, use the “dataStore” option when writing DataFrames.
To set the processing or output spatial reference, use the project tool in the geoanalytics package.
To filter a layer when converting it to a DataFrame, use the “where” or “fields” option when loading the layer’s URL.
To limit the extent of a layer when converting it to a DataFrame, use the “extent” option when loading the layer’s URL.
future
Optional boolean. If
True, a future object will be returned and the process will not wait for the task to complete. The default isFalse, which means wait for results.parameters
Optional dict. A global level variable that will be loaded into the given code. The variable name is called user_variables.
>>> parameters = {"param1": "example", "param2": 1, "val1": 2.0, "more_params": [False, True, None], "status": 4.0}
Only built-in types are supported.
param_as_input
Optional Boolean. If
True,the user_variable will be added if a method past. IfFalse, the variable will not be given into the method.- Returns
Dictionary of messages from the code provided.
# Usage Example: Execute calculate_density tool using run_python_script. def density(): def code(ss=None): import time if ss is None: ss = user_variables['ss'] res = geoanalytics.describe_dataset(input_layer=layers[0], extent_output=True, sample_size=ss) res.write.format('webgis').save('RunPythonScriptTest_{0}'.format(time.time())) run_python_script(code=code, layers=[lyr0], parameters={'ss' : 10000})